튜닝방법을 설명 한바 있다.
오늘은 최적의 Parallel Join 을 하기 위하여 또다른 튜닝방법을 제시한다.
필자가 이글을 쓰는 원래의 용도는 사내 DB 컨설턴트 들을 교육시키는데 사용하는 것이다.
그렇기 때문에 어려워도 실망하거나 우울증에 걸리지 말자.
최근 최진실씨 사태등등 해서 심히 걱정된다.^^
Parallel Join Filter 를 설명하려고 하는데 용어설명부터 해야겠다.
왜냐하면 어떤곳에서는 Parallel Join Filter 라고 이야기 하고 또다른 곳에서는 Bloom Filter 라고 하는데
그이유는 알고리즘을 최초로 개발한 사람이 오라클사의 Burton H. Bloom 이라는 사람이고 이는 1970 년의
일이다.
실제로 실행계획상에 Bloom 의 이름을 따서 필터명이 BF0000, BF0001, BF0003 .... 이렇게 생성된다.
어쨋든 이런사유로 인하여 2개의 용어가 혼용되는데 여기서는 Parallel Join Filter (힌트로는 px_join_filter) 만 사용할것이다.
아래는 테이블 생성 스크립트 이다.
테스트를 위하여 2개의 테이블이 필요하다.
제약사항
Parallel Join Filter 는 10gR2 이상에서 실행가능함.
테스트용 테이블 생성 스크립트
as
with a as
(select /*+ materialize */ level + 10000000 as empno,
chr(mod(level,90)) as big_ename, chr(mod(level,90)) as big_addr
from dual
connect by level <= 100000)
select empno,
lpad(big_ename, 3000,big_ename) as big_ename ,
lpad(big_addr, 3000,big_addr) as big_addr
from a ;
create table emp_2
as
select * from emp_1 ;
EXEC dbms_stats.gather_table_stats(user,'EMP_1');
EXEC dbms_stats.gather_table_stats(user,'EMP_2');
테이블이 생성 되었으므로 테스트 스크립트를 실행시켜보자.
SELECT /*+ full(t1) full(t2) parallel(t1 8) parallel(t2 8) leading(t1) use_hash(t2) NO_PX_JOIN_FILTER(t2) */
*
FROM emp_1 t1,
emp_2 t2
WHERE t1.empno = T2.empno
and t1.BIG_ENAME > '1' ;
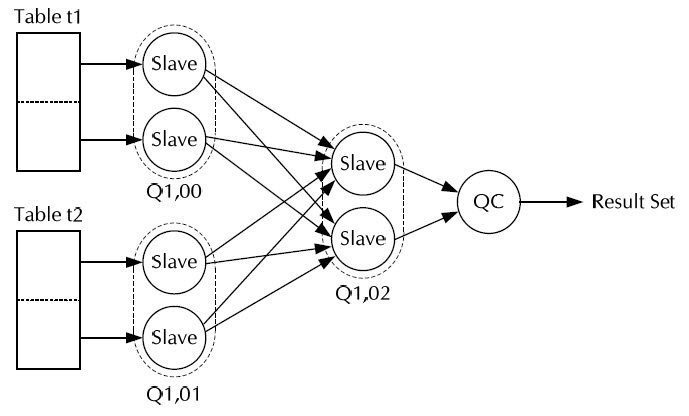
아래 PLAN 을 설명하기전에 일단 TQ(Table queues) 개념을 알아야 한다.
복잡한 plan 같지만 원리를 알고 나면 간단하게 해석 할수 있다.
TQ 는 processes간의 데이터를 주고받는 기능을 한다.
하나의 TQ 는 여러개의 parallel Slave 를 가진다.
아래 PLAN 을 보면 TQ 가 3개(:TQ10000, :TQ10001, TQ10002 ) 생성되어 있다.(파란색 부분)
--------------------------------------------------------------------------------------
| Id | Operation | Name | Cost (%CPU)| TQ |IN-OUT| PQ Distrib |
--------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 12132 (1)| | | |
| 1 | PX COORDINATOR | | | | | |
| 2 | PX SEND QC (RANDOM) | :TQ10002 | 12132 (1)| Q1,02 | P->S | QC (RAND) |
|* 3 | HASH JOIN BUFFERED | | 12132 (1)| Q1,02 | PCWP | |
| 4 | PX RECEIVE | | 3054 (0)| Q1,02 | PCWP | |
| 5 | PX SEND HASH | :TQ10000 | 3054 (0)| Q1,00 | P->P | HASH |
| 6 | PX BLOCK ITERATOR | | 3054 (0)| Q1,00 | PCWC | |
|* 7 | TABLE ACCESS FULL| EMP_1 | 3054 (0)| Q1,00 | PCWP | |
| 8 | PX RECEIVE | | 3054 (0)| Q1,02 | PCWP | |
| 9 | PX SEND HASH | :TQ10001 | 3054 (0)| Q1,01 | P->P | HASH |
| 10 | PX BLOCK ITERATOR | | 3054 (0)| Q1,01 | PCWC | |
| 11 | TABLE ACCESS FULL| EMP_2 | 3054 (0)| Q1,01 | PCWP | |
--------------------------------------------------------------------------------------
각 Id 단위의 설명 :
1. Q1,00 의 slave process 들은 emp_1 테이블을 full scan 하면서 t1.BIG_ENAME > '1' 조건을 FILTER
하였고 process 간의 통신을 위하여 걸러진 데이터를 Q1,02 에 보낸다.
(Id 기준으로 5~7 이 여기에 해당된다)
2. Q1,02 의 slave process 들은 1번에서 받은 데이터들을 이용해 hash table 을 만든다.
(Id 기준으로 3~4 가 여기에 해당된다)
3. Q1,01 의 slave process 들은 emp_1 테이블을 full scan 하고 읽은 데이터를 Q1,02 에 보낸다.
(Id 기준으로 9~11 가 여기에 해당된다)
4. Q1,02 의 slave process 들은 3번에서 던진 데이터를 받아서 미리 만들어진 hash 테이블을
검색하면서 조인작업을 진행하고 결과를 Query Cordinator 에 보낸다.
(Id 기준으로 2~3 이 여기에 해당된다)
5. Query Cordinator 는 각 TQ 로 부터 데이터를 받아서 취합한후에 결과를 Return 한다.
(Id 기준으로 0~1 이 여기에 해당된다)
위설명을 도식화 하면 아래그림과 같다.
다만 위의 SQL 대로라면 각 TQ 내의 SALVE 는 8개 여야 하지만 화면관계상 2개로 줄여서 나타 내었다.
위그림을 보면 무언가 비효율적인 것을 발견하게 된다.
Q1,01 의 모든 SLAVE 들은 Q1,02 의 모든 SLAVE 들에게 똑같은 데이터를 던져서 체크한후에 만족하면
조인에 성공하고 그렇지 않으면 조인에 실패하는 프로세스를 가지게 된다.
위쿼리를 예를들면 사번 10000100을 Q1,02 의 SLAVE 가 8개라면 8번 던져서 1/8 확률로 조인에 성공하면
다행이지만 아예조인에 실패할 확률도 있는것이다.
이런 비효율을 없애는 것이 Parallel Join Filter 이다.
Parallel Join Filter 의 개념은 Q1,01(후행테이블의 TQ) 이 Q1,02 에게 데이터를 전달하기전에 불필요한
데이터를 걸러 낸다는 것이다.
이제 parallel join filter 를 적용시켜보자.
SELECT /*+ full(t1) full(t2) parallel(t1 8) parallel(t2 8) leading(t1) use_hash(t2) PX_JOIN_FILTER(t2) */
*
FROM emp_1 t1,
emp_2 t2
WHERE t1.empno = T2.empno
and t1.BIG_ENAME > '1' ;
필자의 연구결과 t1.ename > '1' 등 t1 의 filter predicate 가 없으면 Parallel Join Filter 는 결코 작동하지 않는다.
그럴때는 t1.empno > 0 등의 결과값의 영향을 끼치지 않는 filter 조건을 주는 트릭을 생각할수 있다.
또하나의 Tip 은 PX_JOIN_FILTER 사용시 후행테이블을 사용하여야 한다는것이다.
왜냐하면 아래의 PLAN 을 보면 Filter 의 생성은 t1 에서 하지만(id 가 4번) 사용은 t2 쪽(id 11번)에서
하기때문에 PX_JOIN_FILTER(t1) 을 주면 절대 filter operation 이 생기지 않는다.
---------------------------------------------------------------------------------------
| Id | Operation | Name | Cost (%CPU)| TQ |IN-OUT| PQ Distrib |
---------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 12132 (1)| | | |
| 1 | PX COORDINATOR | | | | | |
| 2 | PX SEND QC (RANDOM) | :TQ10002 | 12132 (1)| Q1,02 | P->S | QC (RAND) |
|* 3 | HASH JOIN BUFFERED | | 12132 (1)| Q1,02 | PCWP | |
| 4 | PX JOIN FILTER CREATE| :BF0000 | 3054 (0)| Q1,02 | PCWP | |
| 5 | PX RECEIVE | | 3054 (0)| Q1,02 | PCWP | |
| 6 | PX SEND HASH | :TQ10000 | 3054 (0)| Q1,00 | P->P | HASH |
| 7 | PX BLOCK ITERATOR | | 3054 (0)| Q1,00 | PCWC | |
|* 8 | TABLE ACCESS FULL| EMP_1 | 3054 (0)| Q1,00 | PCWP | |
| 9 | PX RECEIVE | | 3054 (0)| Q1,02 | PCWP | |
| 10 | PX SEND HASH | :TQ10001 | 3054 (0)| Q1,01 | P->P | HASH |
| 11 | PX JOIN FILTER USE | :BF0000 | 3054 (0)| Q1,01 | PCWP | |
| 12 | PX BLOCK ITERATOR | | 3054 (0)| Q1,01 | PCWC | |
| 13 | TABLE ACCESS FULL| EMP_2 | 3054 (0)| Q1,01 | PCWP | |
---------------------------------------------------------------------------------------
위 plan 은 원래의 PLAN(filter 적용전 plan) 에서 parallel join filter 부분만이 추가 되었다.(파란색 부분)
1. id 4 에서 parallel Join filter 를 생성(create) 하였고 filter 명은 :BF0000 이다.
2. id 11 에서 생성된 :BF0000 filter 를 사용하였다.
주의사항은 parallel Join filter 를 무조건 사용하지말라는 것이다.
걸러지는 데이터가 별로 없을경우 빨라지지도 않을 뿐더러 filter 부하가 더클수 있기 때문이다.
다음의 2가지 경우에 parallel Join filter 를 사용하여야 한다.
1. 많은양의 데이터가 조인에 실패하는경우
2. 1번을 만족하면서 RAC 에서 multi-node 로 Parallel Query 를 실행한경우.
이경우는대부분 DOP(Degree Of Parallelism)가 클때 발생하며 추가적인 Network I/O 가 발생하므로
parallel join filter 를 적용할경우 획기적인 성능향상을 기대할수 있다.
parallel Join filter에 의해서 filter 된 데이터를 보려면 아래와 같이 v$sql_join_filter 뷰를 사용하면된다.
from v$sql_join_filter
where qc_session_id = sys_context('userenv', 'sid');
결론 :
Parallel Join distribution 과 Parallel join filter 을 적절히 이용하면 최적화된 Parallel Join Query를 만들수 있다.
다시한번 말하지만 꼭필요한 경우에만 이런종류의 힌트를 사용하여야 한다.
편집후기 :만약 parallel Join filter 로직에 관심이 있어서 직접 구현하려면 아래의 1번 문서를 참조하기 바란다.
Reference :
1.Bloom Filters ( Cristian Anatognini )
2.Oracle Corp Manual (Data Warehousing Guide 11g)
'Oracle > Data Join Method' 카테고리의 다른 글
| Hash 조인시 Bushy tree Plan 유도하기 (4) | 2008.11.01 |
|---|---|
| Hash 조인의 튜닝시 주의사항(Work Area 의 튜닝) (3) | 2008.10.30 |
| New Features 의 중요성(Partition Outer Join 의 사용법) (5) | 2008.08.29 |
| Parallel Query 의 조인시 Row Distribution (3) | 2008.07.19 |
| Lateral View 를 활용한 선택적 조인 (2) | 2008.05.29 |





