SQL 은 방정식을 풀기에 적합한 언어인가? 우연히 방정식을 푸는 요건이 있었는데 상황은 아래와 같았다.
요건은 "정수 X 를 정수 Y 로 계속 나누되 N 번 나눈 결과와 N-1 번 나눈 결과의 차이가 0.25 보다 작으면
멈추고 그때까지의 나눈값과 LOOP 횟수( N )를 출력하라" 였다. 물론 X 와 Y 는 변수이다.
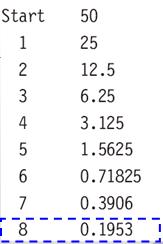
이해를 쉽게 하기 위하여 왼쪽의 그림을 보자.
왼쪽의 그림을 설명하면 50을 2 로 8번 나누면 0.1953 인데 이것을 7번 나눈값으로 빼면 결과는 0.25 이하이다.
따라서 원하는 출력값은 0.1953 과 8 번(LOOP 횟수) 인 것이다.
이요건을 들은 개발자들은 저마다 자바나 PL/SQL 로 개발 하면 된다고 생각했다.
하지만 이기능을 요구한 사람의 말에 따르면 SELECT 쿼리결과로 나오는 것이 가장 좋다.
하지만 불가능하면 자바나 PL/SQL 등으로 구현해도 된다는 것이었다.
여러분이 만약 이러한 요구사항을 해결해야 한다면?
퀴즈라고 생각하고 머릿속에서 해법을 생각해보라.
포기하지마라 사실 필자는 이문제가 성능이슈가 아니었고 SQL을 제법 잘사용하는 개발자들과 DBA 가 회의에 참석하였으므로 직접 나서지 않았는데 한마디 말 때문에 흥분하기 시작했다.
개발자1 : 이것은 SQL 로는 안됩니다. Loop 도 돌려야 하고 Loop 내에서 빠져나가는 로직도 추가해야 되기 때문입니다.
필자 : SQL 로 하는것을 포기 하지마십시오.
개발자1 : 네?
개발자2 : 5분이면 PL/SQL 함수로 구현이 가능할거 같습니다.
그함수를 SQL 에서 call 하면 됩니다. 괜히 고생하지 마시죠.
필자 : 5분이라구요?....그렇다면 두분이서 작성한 코드를 10분뒤에 저에게 보여주세요.
이렇게 해서 회의가 잠시중단이 되었다.
사실 필자는 자주 흥분하는편이 아닌데 언제부터인지 SQL 로는 불가능하며 비효율적이라는 소리를 들을때면 이상하게 자극이 된다. 어쩔수 없는 엔지니어 출신의 비애인것 같다.
It's Time to overhaul!시간이 되어 개발자들이 작성한 코드를 검토해 보았다.
CREATE OR REPLACE function sf_calc(v_value number, v_division number)
return varchar2 as
v_iteration pls_integer := 0;
v_result number;
v_result_before number;
BEGIN
v_result := v_value;
FOR v_counter IN 1..999999999 LOOP
v_result := v_result / v_division;
v_iteration := v_counter;
EXIT WHEN v_iteration > 1 and v_result_before - v_result <= 0.25;
v_result_before = v_result ;
END LOOP;
return '결과 : ' ||to_char(v_result) || ' , '||
'Loop 횟수 : '|| to_char(v_iteration);
END;
위의 함수는 약간 손볼곳이 있지만 그래도 결과에 충실하다. 위의 함수를 SQL 에서 사용하면 아래와 같다.
select sf_calc(50, 2) from dual;
결과 : .1953125 , Loop 횟수 : 8
함수의 길이도 길지않고 이정도면 괜찮다고 말할수 있다. 하지만 또다른 비효율이 숨어 있었다.
결과를 comma (,) 기준으로 잘라서 2 컬럼으로 보여줘야 하는 문제가 여전히 남는다.
그렇다면 필자가 작성한 아래의 SQL 로 바꾸는 것은 어떤가?
select S as "결과", N + 1 as "Loop 횟수" From DUAL
model
dimension by (1 X)
measures ( :v_value S, 0 N) --> :v_value 에 50 대입
rules iterate (999999999) Until (PREVIOUS(S[1])-S[1]<=0.25)
( S[1] = S[1]/ :v_division, --> ::v_division 에 2 대입
N[1] = ITERATION_NUMBER );
결과 Loop 횟수
----------- -----------
0.1953125 8
Model 절 문법이 어렵다고 들었다. 결과가 2컬럼으로 분리되어 정확히 나왔다. 코딩의 시간은 단 1분 이며 코드의 길이는 어떤가? 이정도면 충분히 짧다.
개발자들이 유지보수가 어렵다는 문제를 들고 나왔다. 1분만 투자하면 문법을 익힐수 있음에도 문법이 어렵다는 것은 미신이다.
현재 오라클이 11g 까지 나왔지만 각각의 문법들은 몇분만 투자하면 다 알수 있는 정도이다.
물론 성능면에서 신기능의 실행계획을 분석하는것은 다른 이야기 이다.
간단히 문법을 설명하면 아래와 같다.
1. rules iterate(999999999) 라는 것은 괄호 안의 작업(S[1] = ... 이후생략)을 999999999 번 반복해서 실행한다의 의미이다.
2. Until 이라는것은 Loop 를 빠져나오기 위한 조건을 지정 하는것이다.
3. PREVIOUS(N) 라는 것은 N-1 번째의 값을 의미한다. 따라서 PREVIOUS(S[1])-S[1]<=0.25 의 의미는
"N -1 번째 :v_value 값에서 N 번째 :v_value 값을 뺀 차이가 0.25 이하일때" 인 것이다.
4. S[1] 의 값은 최초에는 :v_value 와 같지만 S[1]/ :v_division 로 계산된 값을 Loop 시마다 대입하므로 값이 계속 바뀐다.
5. N[1] 의 값은 Loop 시마다 1 증가한다. 예약어 ITERATION_NUMBER 의 기능때문이다.
하지만 최초의 값이 0부터 시작되므로 select 시에 1을 더해서 보여줘야 한다.
6. measures ( :v_value S, 0 N) 라는 표현은 단순히 S[1] 과 N[1] 을 사용하기 위하여 단순히 alias 를 정의한것에 불과하다.
주의사항 :
여기서 dimension by 는 아무런 뜻이 없다. 하지만 숫자 1 대신에 다른값을 사용할 경우 SQL 이 종료되지 않으므로 주의해야 한다.
Model 절로 무엇을 할수 있나?
Model 절과 관련된 미신중의 하나는 Time series, 수요예측, 판매예측, 기상예측 등등 주로 이전실적에 여러가지 factor 를 추가하여 미래를 예측하는데 사용하거나 SQL 에서 축이동(Pivot/Unpivot) 등의 용도로만 사용된다고 알고 있다는 것이다. 하지만 위의 SQL 은 이것들중 어디에도 포함되지 않는다. 다시말하면 복잡한 연립방정식을 푸는데 제일좋은 것이 Model 절이다.
결론:
MODEL 절은 오래전(6년전)에 나온 SQL 문법이지만 아직 늦지 않았다. 필자가 확인한 결과 아직도 모르는 사람들이 많이 있으므로 지금 익힌다면 선구자가 될것이다. SQL 은 여러분이 생각하는것보다 훨씬더 강력하고 효율적임을 알수있다. 위의 SQL과 같이 간단하지만 강력한 기능들이 많이 준비되어 있다. 예를들면 X-Query, Regular Expression, Pivot/UnPivot 등이 그것이다. 무기의 종류(SQL)를 여러개 준비한 사람과 기관총 하나만 가지고 있는 사람의 차이는 어마어마 하다. 준비된 사람은 요구조건에 따라서 단검을 사용할것인지 탱크를 사용할것인지 그것도 아니라면 F16 전투기를 사용할것인지 상황에 따라서 맞는 무기를 선택할수 있다. SQL 공부 여기서 포기할것인가?

 invalid-file
invalid-file