-대표적인 페이징 처리방법
-누적집계가 필요할 때 페이징(부분범위) 처리방법
-Pagination의 단점을 이용하는 방법
주의사항
이 글에서 사용되는 분석함수는 현재 row 까지의 누적집계(Cumulative total) 이다. 이와 반대로 전체집계(Grand Total)나 그룹집계(Sub total)는 부분범위처리를 할 수 없다. 왜냐하면 데이터를 모두 읽어야만 결과를 낼 수 있기 때문이다. 하지만 누적집계는 데이터가 sort 되어 있고, 이미 출력된 컬럼들의 값을 알 수 있다면 부분범위처리가 가능하다. 우리는 이점을 이용할 것이다.
상황
Time Out이 발생하여 개발자가 종이 한 장을 들고 급하게 뛰어왔다.
개발자: 페이징 처리를 했고, 최적의 인덱스도 존재하고, 그 인덱스를 잘 타는데도 Time Out이 발생합니다.
필자 : 그럴 리가요?
개발자: 이 SQL입니다. 한번 봐주세요.
필자 : 음….분석함수 때문에 전체 건을 읽고, 전체 건을 sort하는 군요. 페이징 처리방법을 약간 변경하면 됩니다.
개발자: 이 방법은 SQL 작성 가이드에 나온 방법입니다. 이 방법을 쓰지 않으면 사수에게 혼납니다.
필자 : 이 방법을 사용하지 말라는 이야기가 아니라, 분석함수의 위치만 옮기라는 이야기 입니다.
개발자: 그렇군요. 감사합니다.
이렇게 해서 장애상황은 없어졌다. 이후에 SQL 작성가이드에 페이징 처리시 누적집계가 있는 경우의 처리방법을 추가하였다고 한다.
Pagination SQL
개발자가 사용한 페이징 처리용 SQL은 아래와 같았다.
SELECT *
FROM (SELECT a.*, ROWNUM rnum
FROM ( ) a --> 여기에 order by 가 포함된 SQL 을 넣는다.
WHERE ROWNUM <= :v_max_row )
WHERE rnum >= :v_min_row ;
인라인뷰 a에 SQL을 넣기만 하면 페이징 처리가 된다. 물론 조회시 정렬이 필요하다면 order by가 포함된 SQL을 넣어야 한다. 이 방법은 토마스 카이트가 제시하였다. 이 기법은 약간의 비효율이 있다. 첫 페이지에서는 최적이지만, 뒤쪽 페이지를 읽을 때는 이전 페이지의 데이터를 모두 scan 해야 한다.(화면에 출력되지는 않는다.) 하지만 경험적으로 볼 때 비효율이 크지 않다. 왜냐하면 우리가 구글이나 네이버로 검색을 할 때 통상적으로 앞쪽의 몇 페이지만 보고 검색을 끝내기 때문이다. 만약 네이버에서 “트위터”라는 단어로 검색을 했더니 5729 페이지가 나왔다고 치면, 대부분 첫 페이지 혹은 두 번째, 세 번째 페이지에서 찾고자 하는 정보를 볼 수 있을 것이다. 5729 페이지를 모두 넘겨본 사람은 거의 없을 것이다. (만약 있다면 존경스럽다.) 따라서 위의 방법을 사용한다고 해도 성능저하는 거의 발생하지 않는다.
그런데 인라인뷰 a에 포함될 SQL에 누적집계용 분석함수가 포함될 때는 위의 방법에 약간의 변형을 가해야 한다. 그렇지 않고 위의 방법을 그대로 사용하면 심각한 성능저하가 발생할 수 있다. 즉 분석함수가 존재한다면 위의 방법은 무늬만 페이징 처리가 되며 실제로는 전체범위를 처리하여 Time Out이 발생 할 수 있다. 이 글에서는 누적집계용 분석함수가 있는 경우에 기존방법의 문제점을 제시하고 효과인 페이징 처리방법에 대해 논의 한다.
테스트를 위해 테이블과 인덱스를 생성한다.
CREATE TABLE sales_t AS SELECT * FROM sales;
CREATE INDEX ix_prod ON sales_t (prod_id);
먼저 인라인뷰 a 에 들어갈 SQL을 보자.
SQL1
SELECT /*+ INDEX(S IX_PROD) */
s.prod_id, s.cust_id, s.channel_id, s.time_id, amount_sold,
SUM (amount_sold) OVER (PARTITION BY s.cust_id ORDER BY s.channel_id, s.time_id) AS sum_amt
FROM sales_t s
WHERE s.prod_id = :v_prod_id --> 30 대입
ORDER BY s.cust_id, s.channel_id, s.time_id ;
----------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | A-Rows | A-Time | Buffers | Used-Mem |
----------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 29282 |00:00:00.12 | 424 | |
| 1 | WINDOW SORT | | 1 | 29282 |00:00:00.12 | 424 | 1621K (0)|
| 2 | TABLE ACCESS BY INDEX ROWID| SALES_T | 1 | 29282 |00:00:00.10 | 424 | |
|* 3 | INDEX RANGE SCAN | IX_PROD | 1 | 29282 |00:00:00.03 | 60 | |
----------------------------------------------------------------------------------------------------
고객별로 channel_id와 time_id로 sort하여 누적합계를 구하는 SQL이다. 위의 SQL은 페이징 처리(부분범위 처리)가 되지 않은 것이다. 따라서 29282건이 결과로 출력되었고 424 블럭을 Scan 하였다. WINDOW SORT라는 operation이 존재하는 이유는 분석함수 때문이다. SQL에 order by가 있지만 별도의 SORT ORDER BY operation이 존재하지 않는다. 그 이유는 WINDOW SORT가 order by가 할 일을 대신해 주고 있기 때문이다. WINDOW SORT operation 때문에 PGA를 1621K만큼 사용하였다.
이제 페이징 처리를 해보자. 먼저 차이를 보여주기 위하여 분석함수를 제거하고 페이징 처리를 하였다.
SQL2
SELECT *
FROM (SELECT a.*, ROWNUM rnum
FROM (SELECT /*+ INDEX(S IX_PROD) */
s.prod_id, s.cust_id, s.channel_id, s.time_id, amount_sold
FROM sales_t s
WHERE s.prod_id = :v_prod_id --> 30 대입
ORDER BY s.cust_id, s.channel_id, s.time_id
) a
WHERE ROWNUM <= :v_max_row --> 20 대입
)
WHERE rnum >= :v_min_row ; --> 1 대입
-------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | A-Rows | A-Time | Buffers | Used-Mem |
-------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 20 |00:00:00.02 | 424 | |
|* 1 | VIEW | | 1 | 20 |00:00:00.02 | 424 | |
|* 2 | COUNT STOPKEY | | 1 | 20 |00:00:00.02 | 424 | |
| 3 | VIEW | | 1 | 20 |00:00:00.02 | 424 | |
|* 4 | SORT ORDER BY STOPKEY | | 1 | 20 |00:00:00.02 | 424 | 2048 (0)|
| 5 | TABLE ACCESS BY INDEX ROWID| SALES_T | 1 | 29282 |00:00:00.13 | 424 | |
|* 6 | INDEX RANGE SCAN | IX_PROD | 1 | 29282 |00:00:00.03 | 60 | |
-------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("RNUM">=:V_MIN_ROW)
2 - filter(ROWNUM<=:V_MAX_ROW)
4 - filter(ROWNUM<=:V_MAX_ROW)
6 - access("S"."PROD_ID"=:V_PROD_ID)
페이징 처리를 하였음에도 똑같이 전체 블록인 424 블럭을 scan 하였다. 그 이유는 전체 건을 읽어서 정렬작업을 해야 하기 때문이다. 반면에 PGA의 사용은 2048에 불과하다. 왜냐하면 부분범위를 처리할 때는 전체 건을 sort하는 것이 아니라, 20 row 짜리 배열을 만들고 그 배열만 관리하면 되기 때문이다. 자세한 내용은 관련 글을 참조하라.
이제 분석함수를 추가해 보자.
SELECT *
FROM (SELECT a.*, ROWNUM rnum
FROM (SELECT /*+ INDEX(S IX_PROD) */
s.prod_id, s.cust_id, s.channel_id, s.time_id, amount_sold,
SUM(amount_sold) OVER (PARTITION BY s.cust_id ORDER BY s.channel_id, s.time_id) AS sum_amt
FROM sales_t s
WHERE s.prod_id = :v_prod_id --> 30 대입
ORDER BY s.cust_id, s.channel_id, s.time_id
) a
WHERE ROWNUM <= :v_max_row --> 20 대입
)
WHERE rnum >= :v_min_row ; --> 1 대입
-------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | A-Rows | A-Time | Buffers | Used-Mem |
-------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 20 |00:00:00.03 | 424 | |
|* 1 | VIEW | | 1 | 20 |00:00:00.03 | 424 | |
|* 2 | COUNT STOPKEY | | 1 | 20 |00:00:00.03 | 424 | |
| 3 | VIEW | | 1 | 20 |00:00:00.03 | 424 | |
| 4 | WINDOW SORT | | 1 | 20 |00:00:00.03 | 424 | 1621K (0)|
| 5 | TABLE ACCESS BY INDEX ROWID| SALES_T | 1 | 29282 |00:00:00.15 | 424 | |
|* 6 | INDEX RANGE SCAN | IX_PROD | 1 | 29282 |00:00:00.03 | 60 | |
-------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("RNUM">=:V_MIN_ROW)
2 - filter(ROWNUM<=:V_MAX_ROW)
6 - access("S"."PROD_ID"=:V_PROD_ID)
성능저하의 원인은 분석함수
분석함수를 사용하자 PGA사용량이 급격히 늘었다. 분석함수가 없는 경우와 비교해보면 무려 791배나 차이가 난다. SQL1의 PGA 사용량과 위 실행계획의 PGA 사용량을 비교해 보면 분석함수의 PGA 사용량은 페이징 처리를 하지 않았을 때와 똑같다. 즉 페이징 처리를 하였지만 분석함수의 영향으로 전체범위 처리가 되어버린 것이다. 바로 이점이 페이징 처리를 하였음에도 Time-Out이 발생하는 이유였다. 어떻게 하면 비효율을 제거할 수 있을까? 아래의 SQL이 정답이다.
SELECT *
FROM (SELECT s.*, ROWNUM rnum,
SUM (amount_sold) OVER (PARTITION BY s.cust_id ORDER BY s.channel_id, s.time_id) AS sum_amt
FROM (SELECT /*+ INDEX(S IX_PROD) */
s.prod_id, s.cust_id, s.channel_id, s.time_id, amount_sold
FROM sales_t s
WHERE s.prod_id = :v_prod_id --> 30 대입
ORDER BY s.cust_id, s.channel_id, s.time_id
) s
WHERE ROWNUM <= :v_max_row --> 20 대입
)
WHERE rnum >= :v_min_row ; --> 1 대입
--------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | A-Rows | A-Time | Buffers | Used-Mem |
--------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 20 |00:00:00.02 | 424 | |
|* 1 | VIEW | | 1 | 20 |00:00:00.02 | 424 | |
| 2 | WINDOW BUFFER | | 1 | 20 |00:00:00.02 | 424 | 2048 (0)|
|* 3 | COUNT STOPKEY | | 1 | 20 |00:00:00.02 | 424 | |
| 4 | VIEW | | 1 | 20 |00:00:00.02 | 424 | |
|* 5 | SORT ORDER BY STOPKEY | | 1 | 20 |00:00:00.02 | 424 | 2048 (0)|
| 6 | TABLE ACCESS BY INDEX ROWID| SALES_T | 1 | 29282 |00:00:00.14 | 424 | |
|* 7 | INDEX RANGE SCAN | IX_PROD | 1 | 29282 |00:00:00.04 | 60 | |
--------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("RNUM">=:V_MIN_ROW)
3 - filter(ROWNUM<=:V_MAX_ROW)
5 - filter(ROWNUM<=:V_MAX_ROW)
7 - access("S"."PROD_ID"=:V_PROD_ID)
분석함수는 인라인뷰 밖으로 빼라
분석함수를 뷰의 외부로 위치를 바꾸자 PGA를 거의 사용하지 않는다. 분석함수가 추가되었음에도 PGA 사용량이 분석함수를 사용하지 않은 경우(SQL2)와 비슷하다. 그 이유는 20건에 대해서만 분석함수가 실행되었기 때문이다. 즉 ID 2번에서 사용한 PGA는 SORT를 위한 것이 아니다. 왜냐하면 이미 인라인뷰 내에서 SORT가 되었으므로 같은 작업을 반복할 필요가 없기 때문이다. 이런 경우는 order by절의 컬럼과 분석함수 OVER절의 컬럼이 일치한 경우만 나타난다. 이에 따라 Operation도 WINDOW SORT가 아니라 WINDOW BUFFER로 바뀌었다. 즉 20 row로 구성된 배열만 관리하면 된다. Order by 작업 또한 전체 건을 sort하지 않고 페이징 처리된 20건에 대해서 배열만 관리한 것이다.
절반의 성공
위의 실행계획이 best 인가 하면 그렇지는 않다. 왜냐하면 페이징 처리가 되지 않은 SQL1의 실행계획을 보면 29282건을 모두 읽었고, 페이징 처리가 된 위의 SQL 또한 마찬가지 이다. 다시 말해 위의 SQL은 결과적으로 20건만 출력되므로 비효율적인 전체범위를 처리한 것이다. 즉 PGA 사용(Sort)의 관점에서는 부분범위 처리가 되었지만 Block I/O의 관점에서는 전체범위를 처리하고 말았다.
이제 Block I/O 문제를 해결하기 위해 인덱스를 생성해보자.
이제 위의 인덱스를 이용하여 페이징 처리되지 않은 SQL을 실행해 보자.
SELECT /*+ INDEX(S PK_SALES_T) */
s.prod_id, s.cust_id, s.channel_id, s.time_id, amount_sold,
SUM (amount_sold) OVER (PARTITION BY s.cust_id ORDER BY s.channel_id, s.time_id) AS sum_amt
FROM sales_t s
WHERE s.prod_id = :v_prod_id --> 30 대입
ORDER BY s.cust_id, s.channel_id, s.time_id ;
-------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | A-Rows | A-Time | Buffers | Used-Mem |
-------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 29282 |00:00:00.11 | 28337 | |
| 1 | WINDOW BUFFER | | 1 | 29282 |00:00:00.11 | 28337 | 1495K (0)|
| 2 | TABLE ACCESS BY INDEX ROWID| SALES_T | 1 | 29282 |00:00:00.12 | 28337 | |
|* 3 | INDEX RANGE SCAN | PK_SALES_T | 1 | 29282 |00:00:00.03 | 118 | |
-------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("S"."PROD_ID"=:V_PROD_ID)
28337 블록을 scan 하였고 PGA를 1495K나 사용하였다. WINDOW BUFFER operation을 본다면 전체 건을 sort한 것은 아니다. 하지만 배열(WINDOW)의 크기가 20건이 아니라 29282건이나 되므로 전체 건을 sort한 경우와 PGA 사용량이 비슷해져 버렸다. 전체 건을 sort한 SQL1의 PGA 사용량이 1621K 이므로 비슷하다고 할 수 있다.
페이징 처리를 해도...
이런 현상은 페이징 처리를 해도 분석함수를 인라인뷰 외부로 이동하지 않으면 마찬가지로 발생한다. 아래의 SQL을 보자.
SELECT *
FROM (SELECT a.*, ROWNUM rnum
FROM (SELECT /*+ INDEX(S PK_SALES_T) */
s.prod_id, s.cust_id, s.channel_id, s.time_id, amount_sold,
SUM (amount_sold) OVER (PARTITION BY s.cust_id ORDER BY s.channel_id, s.time_id) AS sum_amt
FROM sales_t s
WHERE s.prod_id = :v_prod_id --> 30 대입
ORDER BY s.cust_id, s.channel_id, s.time_id
) a
WHERE ROWNUM <= :v_max_row --> 20 대입
)
WHERE rnum >= :v_min_row ; --> 1 대입
----------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | A-Rows | A-Time | Buffers | Used-Mem |
----------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 20 |00:00:00.04 | 28337 | |
|* 1 | VIEW | | 1 | 20 |00:00:00.04 | 28337 | |
|* 2 | COUNT STOPKEY | | 1 | 20 |00:00:00.04 | 28337 | |
| 3 | VIEW | | 1 | 20 |00:00:00.04 | 28337 | |
| 4 | WINDOW BUFFER | | 1 | 20 |00:00:00.04 | 28337 | 1495K (0)|
| 5 | TABLE ACCESS BY INDEX ROWID| SALES_T | 1 | 29282 |00:00:00.13 | 28337 | |
|* 6 | INDEX RANGE SCAN | PK_SALES_T | 1 | 29282 |00:00:00.03 | 118 | |
----------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("RNUM">=:V_MIN_ROW)
2 - filter(ROWNUM<=:V_MAX_ROW)
6 - access("S"."PROD_ID"=:V_PROD_ID)
부분범위 처리가 아니라 전체범위 처리이다
많은 이들이 착각하는 것이 위의 SQL이다. 다시 말해 “order by와 분석함수의 over절에 최적화된 인덱스를 생성하면 부분처리가 되겠지” 라고 생각한다. 하지만 사실은 이와 다르다. 인덱스의 영향으로 Plan상에 sort order by와 window sort operation이 없으므로 부분범위 처리가 된 것으로 판단하면 안 된다. 20건을 읽은 것이 아니라 전체 건인 29282건을 읽었으며 PGA 사용량도 전체 건을 sort했던 경우(SQL1)와 비슷하다.
이런 상황에서도 해결방법은 분석함수를 밖으로 빼는 것이다. 아래의 SQL을 보자.
SELECT *
FROM (SELECT s.*, ROWNUM rnum,
SUM (amount_sold) OVER (PARTITION BY s.cust_id ORDER BY s.channel_id, s.time_id) AS sum_amt
FROM (SELECT /*+ INDEX(S PK_SALES_T) */
s.prod_id, s.cust_id, s.channel_id, s.time_id, amount_sold
FROM sales_t s
WHERE s.prod_id = :v_prod_id --> 30 대입
ORDER BY s.cust_id, s.channel_id, s.time_id
) s
WHERE ROWNUM <= :v_max_row --> 20 대입
)
WHERE rnum >= :v_min_row ; --> 1 대입
----------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | A-Rows | A-Time | Buffers | Used-Mem |
----------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 20 |00:00:00.01 | 23 | |
|* 1 | VIEW | | 1 | 20 |00:00:00.01 | 23 | |
| 2 | WINDOW BUFFER | | 1 | 20 |00:00:00.01 | 23 | 2048 (0)|
|* 3 | COUNT STOPKEY | | 1 | 20 |00:00:00.01 | 23 | |
| 4 | VIEW | | 1 | 20 |00:00:00.01 | 23 | |
| 5 | TABLE ACCESS BY INDEX ROWID| SALES_T | 1 | 20 |00:00:00.01 | 23 | |
|* 6 | INDEX RANGE SCAN | PK_SALES_T | 1 | 20 |00:00:00.01 | 3 | |
----------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("RNUM">=:V_MIN_ROW)
3 - filter(ROWNUM<=:V_MAX_ROW)
6 - access("S"."PROD_ID"=:V_PROD_ID)
정확히 20건에 대해서만 WINDOW BUFFER operation 이 발생하였다. 이에 따라 PGA 사용량도 최적이 되었다. 또한 Block I/O 관점에서도 최상이다. 28337 Block을 scan한 것이 아니라 고작 23 Block을 scan 하였다. 분석함수의 위치가 성능에 얼마나 큰 영향을 미치는지 알 수 있는 장면이다.
결론
페이징 처리가 되었음에도 Time Out이 발생한다면 누적집계용 분석함수를 의심해보아야 한다. 만약 분석함수가 존재한다면 인라인뷰 밖으로 빼야 한다. 그렇게 한다면 분석함수의 실행이 최소화되며 이에 따라 성능이 향상된다. 또한 order by와 분석함수에 최적화된 인덱스를 만든다면 전체 건을 읽지 않아도 되며 sort의 부하 또한 없어질 것이다. 다시 말해 비효율이 없는 페이징 처리가 가능하다.
원리는 따로 있다
이 글의 결론까지 보았음에도 한가지 의문점을 떠올리지 못한다면 핵심원리를 놓친 것이다. 의문점이란 “분석함수를 인라인뷰 밖으로 빼도 답이 달라지지 않는가?” 이다. 분석함수를 인라인뷰 밖으로 빼는 방법이 가능한 이유가 뭐라고 생각하는가? 답을 보기 전에 잠시 이유를 생각해보기 바란다. 답은 아래에 있다.
답을 보려면 아래의 글을 마우스로 드래그 하시오
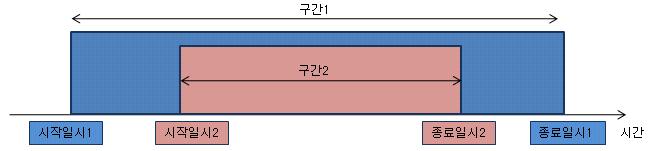
이 글의 처음에 언급했던 페이징 처리시 약간의 비효율 있다고 했는데 이것이 원리이다. Tomas Kyte가 제시한 pagination 방법을 사용하면 뒤쪽 페이지를 읽을 때는 이전 페이지의 데이터를 모두 scan 해야 만 한다. 이 비효율을 이용하는 것이 핵심이다. 왜냐하면 한 페이지의 누적집계를 구하려면 이전 페이지의 값들을 모두 알아야 하기 때문이다. 예를 들어 홍길동 고객의 실적이 1 페이지와 2 페이지에 걸쳐서 나온다고 할 때, 1 페이지 있는 홍길동의 실적과 2페이지에 있는 홍길동의 실적을 더해야만 2 페이지의 누적집계를 구할 수 있다. 그런데 위의 방법을 사용하면 분석함수를 인라인뷰 밖으로 빼더라도 이전 페이지의 값을 보존하기 때문에 누적집계의 값은 정확하다.
“페이징 처리시 누적집계용 분석함수를 인라인뷰 밖으로 빼라”고 누군가에게 guide할 때 단점(비효율)을 장점으로 이용했음을 같이 알려주기 바란다. 그것이 원리이자 핵심이기 때문이다.
PS
즐거운 성탄절을 보내시기 바랍니다.
지난 1년간 이 블로그를 이용해 주셔서 감사합니다.
'Oracle > SQL Tuning' 카테고리의 다른 글
| Sort 부하를 좌우하는 두 가지 원리 (11) | 2011.03.29 |
|---|---|
| SQL튜닝 방법론 (20) | 2011.01.27 |
| 오라클의 Update문은 적절한가? (15) | 2010.04.14 |
| Connect By VS ANSI SQL (7) | 2010.02.11 |
| USE_CONCAT 힌트 제대로 알기 (5) | 2009.07.17 |
 invalid-file
invalid-file