필자는 예전에 Recursive SQL이라는 글을 통하여 IBM DB2나 Microsoft의 SQL Serve에서 사용하는 Recursive With문을 소개한적이 있다. 시간이 흘러 이제는 Oracle11gR2에서 Recursive With문을 사용할 수 있게 되었다. 오라클에서도 DB2나 SQL Serve처럼 ANSI SQL을 사용할 수 있게 된 것이다.
타 DBMS에 능숙한 사람들에게는 환영할만한 일이나 오라클을 사용한 사람들은 별로 달가워하지 않는 것 같다. 왜냐하면 기존의 오라클 사용자들은 Connect By의 기능이 워낙 막강하였으므로 굳이 ANSI SQL을 사용할 필요가 없다고 생각하기 때문이다.
하지만 과연 그럴까? 모든 기능은 용도가 있다.
이 글을 보고 알 수 있는 사항은 다음과 같다.
1. Connect By와 Recursive With의 문법 비교
2. Connect By와 Recursive With의 기능 비교
3. Connect By와 Recursive With의 성능 비교
4. 1, 2, 3번을 통하여 Connect By와 Recursive With의 장단점 파악
1) 문법 관점에서 Connect By VS Recursive With
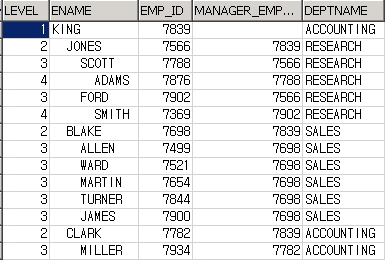
SELECT employee_id, first_name, manager_id, LEVEL
FROM employee
START WITH manager_id IS NULL
CONNECT BY PRIOR employee_id = manager_id;
EMPLOYEE_ID FIRST_NAME MANAGER_ID LEVEL
----------- -------------------- ---------- ----------
100 Steven 1
101 Neena 100 2
108 Nancy 101 3
109 Daniel 108 4
110 John 108 4
...중간생략
202 Pat 201 3
107 rows selected.
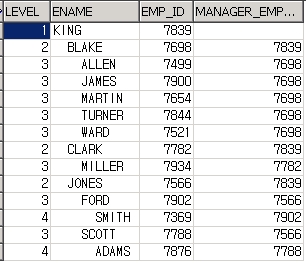
WITH recursive(employee_id, name, manager_id, recursive_level) AS
( SELECT employee_id, first_name, manager_id, 1 recursive_level
FROM employee
WHERE manager_id IS NULL --> START WITH 절에 해당함
UNION ALL
SELECT e.employee_id, e.first_name, e.manager_id, recursive_level + 1
FROM employee e, recursive
WHERE e.manager_id = recursive.employee_id --> CONNECT BY 절에 해당함
)
SELECT *
FROM recursive;
EMPLOYEE_ID NAME MANAGER_ID RECURSIVE_LEVEL
----------- -------------------- ---------- ---------------
100 Steven 1
201 Michael 100 2
101 Neena 100 2
102 Lex 100 2
114 Den 100 2
...중간생략
107 Diana 103 4
107 rows selected.
SQL문이 길어졌다. 하지만 가독성은?
위의 예제에서 볼 수 있듯이 Recursive With 문은 Connect By에 비하여 가독성이 좋아졌다. 왜냐하면 시작조건과 찾아가는 조건이 Union All로 분기되어 있으므로 SQL이 조금 길어지긴 하였으나 해석하는데 전혀 어려운 점이 없기 때문이다. 또한 SQL이 분리되어 있으므로 각각의 성능 최적화도 쉽게 할 수 있다. 주의 사항이 있다. Recursive With 문에서는 LEVEL을 사용할 수 없지만 위의 경우처럼 숫자 초기값을 지정하고 거기에 1을 계속 더해가면 같은 기능을 사용할 수 있다. 또 하나의 주의사항은 Sort의 순서가 다르다는 것인데 Order By 기능을 설명하는 부분에서 자세히 다루어진다.
무한루프 발생 테스트
먼저 무한루프에 만들기 위하여 TOP LEVEL의 manager를 조작하고 Connect By와 Recursive With문을 각각 실행시켜보자.
UPDATE employee
SET manager_id = 101
WHERE employee_id = 100;
commit;
SELECT employee_id, first_name, manager_id, LEVEL
FROM employee
START WITH manager_id = 100
CONNECT BY PRIOR employee_id = manager_id;
ORA-01436: CONNECT BY loop in user data
WITH recursive(employee_id, name, manager_id, recursive_level) AS
( SELECT employee_id, first_name, manager_id, 1 recursive_level
FROM employee
WHERE manager_id = 100
UNION ALL
SELECT e.employee_id, e.first_name, e.manager_id, recursive_level + 1
FROM employee e, recursive
WHERE e.manager_id = recursive.employee_id
)
SELECT *
FROM recursive;
ORA-32044: cycle detected while executing recursive WITH query
위에서 보는 것처럼 에러코드가 서로 다르다. 기존의 Connect By문은 이러한 무한루프를 성공적으로 제거하는 기능이 존재했다. 아래가 그 기능을 구현한 SQL이다.
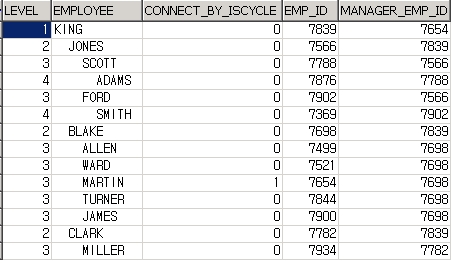
SELECT employee_id,
manager_id,
CONNECT_BY_ISCYCLE AS iscycle
FROM employee
START WITH employee_id = 100
CONNECT BY NOCYCLE PRIOR employee_id = manager_id ;
107 rows selected.
Connect By절에 NOCYCLE을 명시하면 무한루프를 방지할 수 있다. 뿐만 아니라 CONNECT_BY_ISCYCLE 기능을 사용하면 무한루프를 발생시키는 Row를 발견할 수 있다. 또한 Oracle 9i와 10g를 거치면서 기능이 막강해져서 아래와 같이 사용할 수 있게 되었다.
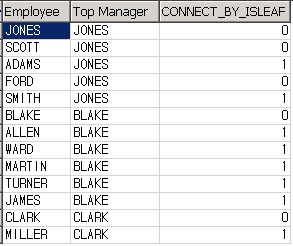
SELECT employee_id,
manager_id,
LTRIM(SYS_CONNECT_BY_PATH (last_name, '-'),'-') as name_tree,
CONNECT_BY_ROOT last_name as root_name,
CONNECT_BY_ISLEAF as isleaf,
CONNECT_BY_ISCYCLE as iscycle
FROM employee
START WITH employee_id = 100
CONNECT BY NOCYCLE PRIOR employee_id = manager_id
ORDER SIBLINGS BY employee_id ;
107 rows selected.
위의 기능 중에 하나라도 모르는 것이 있다면 Hierarchical Queries를 참조하라
2) 기능 관점에서 Connect By VS Recursive With
위에서 보았던 막강한 기능들을 Recursive With에서 모두 사용할 수 있는지 아닌지는 매우 중요하다. 왜냐하면 기능의 사용 가능 유무에 의해서 Recursive With의 존재가치가 판가름 날 것이기 때문이다. 위의 예제에서 사용한 모든 기능들을 Recursive With문에서 사용할 수 있으면 좋겠지만 아쉽게도 위에서 굵게 표시된 모든 예약어와 함수 등을 사용할 수 없다. 하지만 Recursive With문에서는 모든 기능을 예약어나 함수가 아닌 수동으로 재연할 수 있다. 그것도 아주 간편하게 말이다. 손 맛을 느끼게 해주는 SQL이다. 아래를 보자.
WITH recursive(employee_id, manager_id, name_tree) as
( SELECT employee_id, manager_id, last_name
FROM employee
WHERE employee_id = 100
UNION ALL
SELECT e.employee_id, e.manager_id,
recursive.name_tree||'-'||e.last_name --> SYS_CONNECT_BY_PATH 함수에 해당함
FROM employee e, recursive
WHERE e.manager_id = recursive.employee_id
)
SEARCH DEPTH FIRST BY employee_id SET IDX --> ORDER SIBLINGS BY 기능에 해당함
CYCLE manager_id SET iscycle TO "1" DEFAULT "0" --> CONNECT_BY_ISCYCLE 기능에 해당함
SELECT employee_id, manager_id, name_tree,
regexp_substr(name_tree, '[^-]*' ) root_name, --> CONNECT_BY_ROOT 기능에 해당함
decode( regexp_count(lead(name_tree) OVER(ORDER BY IDX), name_tree), 0, 1, null, 1, 0) isleaf,
--> CONNECT_BY_ISLEAF 기능에 해당함
iscycle
FROM recursive;
102 rows selected.
이것 봐라?
너무나 쉽게 기능을 구현하였다. 이 정도라면 기존의 Connect By 사용자도 “어라 이것 봐라?” 라고 이야기 할 것이다. 기능을 살펴보자. 먼저 SEARCH DEPTH FIRST BY 기능은 ORDER SIBLINGS BY 기능에 해당한다. 물론 employee_id 컬럼에 ASC나 DESC를 사용할 수 있다. SET IDX라는 기능은 Sort된 순서대로 일련번호를 생성하는 기능이다. 이것은 ROWNUM과 기능이 비슷하지만 다른 점은 정렬된 순서대로 채번된다는 것이다. 주의사항은 SEARCH DEPTH FIRST 기능을 사용하지 않고 보통의 Order By 구문을 사용하게 되면 Tree 구조가 유지되지 않는다는 것이다. 이런 관점은 Connect By의 ORDER SIBLINGS BY 기능과 같다.
CYCLE manager_id SET iscycle TO "1" DEFAULT "0" 라고 선언하면 manager_id의 값이 잘못되어 무한루프가 발생될 때 식별할 수 있다. 이때 iscycle을 가상의 컬럼으로 이용하게 된다. 주의사항은 iscycle의 값은 숫자가 될 수 없으며 1 Byte 문자만 가능하다. “1” 과 “0”을 사용한 이유도 여기에 있다. regexp_substr를 사용한 이유는 문자를 첫번째 ‘-‘ 까지 잘라내야 root_name을 구할 수 있기 때문이다. Regular Expression에 대하여 자세히 알고 싶은 독자는 오라클 Regular Expressions 완전정복을 참조하라. regexp_count는 버전 11g에 추가된 기능이다. 이 기능은 다음처럼 사용할 수 있다.
ex) regexp_count(text1, text2) :
text1에 text2가 포함된 횟수를 Return한다. 예를 들면 regexp_count(‘yahoo.co.kr’, ‘o’) 라고 했다면 o 가 3번 포함되어 있으므로 3이 Return 된다.
건수가 차이 난다
하지만 문제가 있다. 결과건수가 차이가 난다. Connect By는 결과가 107건이며 Recursive With문은 102건을 Return 하였다. 이 5건의 차이는 무엇인가? 아래는 차이의 분석을 위하여 두 SQL의 결과값 중에서 필요한 부분만 표로 정리한 것이다.
|
Connect By 사용 |
Recursive With 사용 |
|
EMP_ID |
NAME_TREE |
IS
CYCLE |
EMP_ID |
NAME_TREE |
IS
CYCLE |
|
101 |
King-Kochhar |
1 |
101 |
King-Kochhar |
0 |
|
출력되지 않음 |
100 |
King-Kochhar-King |
1 |
|
204 |
King-Kochhar-Baer |
0 |
204 |
King-Kochhar-Baer |
1 |
|
108 |
King-Kochhar-Greenberg |
0 |
108 |
King-Kochhar-Greenberg |
1 |
|
110 |
King-Kochhar-Greenberg-Chen |
0 |
출력되지 않음 |
|
109 |
King-Kochhar-Greenberg-Faviet |
0 |
|
113 |
King-Kochhar-Greenberg-Popp |
0 |
|
111 |
King-Kochhar-Greenberg-Sciarra |
0 |
|
112 |
King-Kochhar-Greenberg-Urman |
0 |
|
205 |
King-Kochhar-Higgins |
0 |
205 |
King-Kochhar-Higgins |
1 |
|
206 |
King-Kochhar-Higgins-Gietz |
0 |
출력되지 않음 |
|
203 |
King-Kochhar-Mavris |
0 |
203 |
King-Kochhar-Mavris |
1 |
|
200 |
King-Kochhar-Whalen |
0 |
200 |
King-Kochhar-Whalen |
1 |
어떤 차이가 있나?
결론을 이야기하면 Connect By의 NoCycle, IsCycle 기능과 Recursive With의 Cycle및 IsCycle 기능과는 차이가 있다.즉 각각의 기능이 다르므로 용도를 구분할 줄 알아야 한다는 뜻이다.
Connect By의 NoCycle 기능은 King과 Kochhar의 관계가 반복되는 것을 Skip하고 표시된다. 즉 직원번호 204의 name_tree 항목을 보면 King-Kochhar-Baer 라고 되어 있지만 사실은 King-Kochhar- King-Kochhar - King-Kochhar ....무한반복... Baer 처럼 표시할 수 있다. 하지만 Connect By + NoCycle을 사용하면 무한반복을 Skip하고 한번만 나타낸다. 또한 IsCycle 도 반복이 시작되기 직전의 데이터를 식별해주는 기능을 한다.
Connect By + NoCycle을 사용하면 직원번호 101의 데이터는 Cycle 로 표시되는데 사실은 아직 Cycle이 아니다. 왜냐하면 오른쪽의 Recursive With를 사용한 경우를 보면 직원번호 100번의 데이터는 King-Kochhar-King인데 King이 두 번 반복 된 것을 볼 수 있고 이 경우가 첫 번째 반복되는 Cycle 이기 때문이다. Recursive With의 IsCycle 항목에는 이런 관점이 잘 반영되어 나타난다. 이 데이터는 Connect By + NoCycle을 사용하면 볼 수 없다.
마지막으로 Connect By를 사용하면 데이터가 출력되지만 Recursive With를 사용하면 출력되지 않는 Row가 있다. 그 이유는 Connect By는 관계의 반복만 제거하고 마지막까지 데이터를 찾아가지만 Recursive With는 반복되는 첫 번째 데이터만 찾고 거기서 멈춘다. 즉 Connect By를 사용하면 King-Kochhar-Greenberg-Chen로 데이터의 끝까지 찾아가지만 Recursive With를 사용하면 King-Kochhar-Greenberg 여기서 멈춘다. 위의 표를 유심히 비교해 보기 바란다. 지금까지 문법과 여러 가지 기능의 차이를 알아보았다.
3) 성능관점에서 Connect By VS Recursive With
이제 가장 중요한 성능을 비교해보자.
SELECT /*+ GATHER_PLAN_STATISTICS */
employee_id,
manager_id,
LTRIM(SYS_CONNECT_BY_PATH (last_name, '-'),'-') name_tree,
CONNECT_BY_ROOT last_name root_name,
CONNECT_BY_ISLEAF isleaf,
TO_CHAR(CONNECT_BY_ISCYCLE) iscycle
FROM employee
START WITH employee_id = 100
CONNECT BY NOCYCLE PRIOR employee_id = manager_id
ORDER SIBLINGS BY employee_id;
--------------------------------------------------------------------------------------
| Id | Operation | Name | A-Rows | Buffers | Used-Mem |
--------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 107 | 16 | |
|* 1 | CONNECT BY WITH FILTERING | | 107 | 16 | 2048 (0)|
| 2 | TABLE ACCESS BY INDEX ROWID | EMPLOYEE | 1 | 2 | |
|* 3 | INDEX UNIQUE SCAN | EMP_EMP_ID_PK | 1 | 1 | |
| 4 | NESTED LOOPS | | 106 | 14 | |
| 5 | CONNECT BY PUMP | | 107 | 0 | |
| 6 | TABLE ACCESS BY INDEX ROWID| EMPLOYEE | 106 | 14 | |
|* 7 | INDEX RANGE SCAN | EMP_MANAGER_IX | 106 | 5 | |
--------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("MANAGER_ID"=PRIOR NULL)
3 - access("EMPLOYEE_ID"=100)
7 - access("connect$_by$_pump$_002"."PRIOR employee_id "="MANAGER_ID")
WITH recursive(employee_id, manager_id, name_tree) as
( SELECT employee_id, manager_id, last_name
FROM employee
WHERE employee_id = 100
UNION ALL
SELECT e.employee_id, e.manager_id,
recursive.name_tree||'-'||e.last_name
FROM employee e, recursive
WHERE e.manager_id = recursive.employee_id
)
SEARCH DEPTH FIRST BY employee_id SET IDX
CYCLE manager_id SET iscycle TO "1" DEFAULT "0"
SELECT /*+ GATHER_PLAN_STATISTICS */
employee_id, manager_id, name_tree,
regexp_substr(name_tree, '[^-]*' ) root_name,
decode(regexp_count(lead(name_tree) OVER(ORDER BY IDX), name_tree), 0, 1, null, 1, 0) isleaf,
iscycle
FROM recursive;
-------------------------------------------------------------------------------------------------
| Id | Operation | Name | A-Rows | Buffers | Used-Mem |
-------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 107 | 16 | |
| 1 | WINDOW BUFFER | | 107 | 16 | 8192 (0)|
| 2 | VIEW | | 107 | 16 | |
| 3 | UNION ALL (RECURSIVE WITH) DEPTH FIRST| | 107 | 16 | |
| 4 | TABLE ACCESS BY INDEX ROWID | EMPLOYEE | 1 | 2 | |
|* 5 | INDEX UNIQUE SCAN | EMP_EMP_ID_PK | 1 | 1 | |
| 6 | NESTED LOOPS | | 106 | 14 | |
| 7 | NESTED LOOPS | | 106 | 5 | |
| 8 | RECURSIVE WITH PUMP | | 107 | 0 | |
|* 9 | INDEX RANGE SCAN | EMP_MANAGER_IX | 106 | 5 | |
| 10 | TABLE ACCESS BY INDEX ROWID | EMPLOYEE | 106 | 9 | |
-------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
5 - access("EMPLOYEE_ID"=100)
9 - access("E"."MANAGER_ID"="RECURSIVE"."EMPLOYEE_ID")
IsLeaf 기능을 사용하려면 Connect By가 유리하다
Scan한 블럭수는 16으로 동일하다. 하지만 PGA 사용량이 4배나 차이 난다. 하지만 이것은 Connect By와 Recursive With의 성능 차이가 아니라 분석함수 lead의 사용 유무에 의한 차이이다. 즉 IsLeaf 기능이 필요하다면 기존의 Connect By를 사용하는 것이 유리할 것이다. 하지만 Connect By나 Recursive With 자체의 성능만 비교한다면 결과가 달라진다.
Connect By와 Recursive With에서 IsLeaf 항목을 빼고 다시 실행 해보자.
SELECT /*+ GATHER_PLAN_STATISTICS */
employee_id,
manager_id,
LTRIM(SYS_CONNECT_BY_PATH (last_name, '-'),'-') name_tree,
CONNECT_BY_ROOT last_name root_name,
TO_CHAR(CONNECT_BY_ISCYCLE) iscycle
FROM employee
START WITH employee_id = 100
CONNECT BY NOCYCLE PRIOR employee_id = manager_id
ORDER SIBLINGS BY employee_id;
--------------------------------------------------------------------------------------
| Id | Operation | Name | A-Rows | Buffers | Used-Mem |
--------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 107 | 16 | |
|* 1 | CONNECT BY WITH FILTERING | | 107 | 16 | 2048 (0)|
| 2 | TABLE ACCESS BY INDEX ROWID | EMPLOYEE | 1 | 2 | |
|* 3 | INDEX UNIQUE SCAN | EMP_EMP_ID_PK | 1 | 1 | |
| 4 | NESTED LOOPS | | 106 | 14 | |
| 5 | CONNECT BY PUMP | | 107 | 0 | |
| 6 | TABLE ACCESS BY INDEX ROWID| EMPLOYEE | 106 | 14 | |
|* 7 | INDEX RANGE SCAN | EMP_MANAGER_IX | 106 | 5 | |
--------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("MANAGER_ID"=PRIOR NULL)
3 - access("EMPLOYEE_ID"=100)
7 - access("connect$_by$_pump$_002"."PRIOR employee_id "="MANAGER_ID")
WITH recursive(employee_id, manager_id, name_tree) as
( SELECT employee_id, manager_id, last_name
FROM employee
WHERE employee_id = 100
UNION ALL
SELECT e.employee_id, e.manager_id,
recursive.name_tree||'-'||e.last_name
FROM employee e, recursive
WHERE e.manager_id = recursive.employee_id
)
SEARCH DEPTH FIRST BY employee_id SET IDX
CYCLE manager_id SET iscycle TO "1" DEFAULT "0"
SELECT /*+ GATHER_PLAN_STATISTICS */
employee_id, manager_id, name_tree,
regexp_substr(name_tree, '[^-]*' ) root_name,
iscycle
FROM recursive;
-------------------------------------------------------------------------------------
| Id | Operation | Name | A-Rows | Buffers |
-------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 107 | 16 |
| 1 | VIEW | | 107 | 16 |
| 2 | UNION ALL (RECURSIVE WITH) DEPTH FIRST| | 107 | 16 |
| 3 | TABLE ACCESS BY INDEX ROWID | EMPLOYEE | 1 | 2 |
|* 4 | INDEX UNIQUE SCAN | EMP_EMP_ID_PK | 1 | 1 |
| 5 | NESTED LOOPS | | 106 | 14 |
| 6 | NESTED LOOPS | | 106 | 5 |
| 7 | RECURSIVE WITH PUMP | | 107 | 0 |
|* 8 | INDEX RANGE SCAN | EMP_MANAGER_IX | 106 | 5 |
| 9 | TABLE ACCESS BY INDEX ROWID | EMPLOYEE | 106 | 9 |
-------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
4 - access("EMPLOYEE_ID"=100)
8 - access("E"."MANAGER_ID"="RECURSIVE"."EMPLOYEE_ID")
일반적인 경우 Recursive With가 유리함
보았는가? 상황이 역전되어 Recursive With를 사용하면 PGA를 전혀 사용하지 않는다. 따라서 IsLeaf를 사용하지 않는 일반적인 경우 Recursive With가 유리함을 알 수 있다.
대용량 배치일 경우 Recursive With를 주의하라
하지만 이것이 끝이 아니다. 대용량 배치일 경우는 상황이 다시 반전된다.
WITH recursive(employee_id, name, manager_id, recursive_level) AS
( SELECT employee_id, first_name, manager_id, 1 recursive_level
FROM employee
WHERE manager_id IS NULL
UNION ALL
SELECT e.employee_id, e.first_name, e.manager_id, recursive_level + 1
FROM employee e, recursive
WHERE e.manager_id = recursive.employee_id
)
SELECT /*+ GATHER_PLAN_STATISTICS */ *
FROM recursive;
---------------------------------------------------------------------------------------
| Id | Operation | Name | A-Rows | Buffers |
---------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 107 | 22 |
| 1 | VIEW | | 107 | 22 |
| 2 | UNION ALL (RECURSIVE WITH) BREADTH FIRST| | 107 | 22 |
|* 3 | TABLE ACCESS FULL | EMPLOYEE | 1 | 8 |
| 4 | NESTED LOOPS | | 106 | 14 |
| 5 | NESTED LOOPS | | 106 | 5 |
| 6 | RECURSIVE WITH PUMP | | 107 | 0 |
|* 7 | INDEX RANGE SCAN | EMP_MANAGER_IX | 106 | 5 |
| 8 | TABLE ACCESS BY INDEX ROWID | EMPLOYEE | 106 | 9 |
---------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - filter("MANAGER_ID" IS NULL)
7 - access("E"."MANAGER_ID"="RECURSIVE"."EMPLOYEE_ID")
대용량 배치일 경우 Recursive With는 비효율이 발견되었다. manager_id IS NULL 조건 때문에 EMPLOYEE 테이블을 Full Scan 하였지만 Union ALL 아래의 SQL에서 또다시 EMPLOYEE 테이블을 Scan하고 있다. 동일한 블록을 두 번 Scan한 셈이다. 하지만 아래를 보라.
SELECT /*+ GATHER_PLAN_STATISTICS */ employee_id, first_name, manager_id, LEVEL
FROM employee
START WITH manager_id IS NULL
CONNECT BY PRIOR employee_id = manager_id;
-------------------------------------------------------------------------------
| Id | Operation | Name | A-Rows | Buffers |
-------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 107 | 7 |
|* 1 | CONNECT BY NO FILTERING WITH START-WITH| | 107 | 7 |
| 2 | TABLE ACCESS FULL | EMPLOYEE | 107 | 7 |
-------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("MANAGER_ID"=PRIOR NULL)
filter("MANAGER_ID" IS NULL)
Connect By를 사용하면 Union을 사용하지 않으므로 Full Table Scan 한 번으로 끝낼 수 있다. Scan한 블럭수는 세 배 이상 차이가 난다.
Connect By VS Recursive With 의 결론
1) 문법적인 측면에서 거의 차이가 없다. Recursive With가 조금 길어지기는 하지만 Union All로 분리되어 있기 때문에 오히려 가독성과 성능 최적화가 쉽게 될 수 있다.
2) 기능면에서도 거의 차이가 없다. Connect By의 모든 기능이 구현 가능하다. 다만 Nocycle 기능과 IsCycle 기능의 용도가 서로 다르므로 구분해서 사용하면 된다.
3) 성능면에서는 Sort 기능을 사용해도 PGA를 전혀 사용하지 않는 Recursive With가 일반적으로 유리하다. 하지만 IsLeaf 기능을 구현하려면 분석함수를 사용해야 하기 때문에 Connect By가 유리할 수 있다. 또한 Scan할 범위가 넓은 경우 Start With 조건을 Full Table Scan으로 유도하면 같은 블럭을 반복해서 Scan하지 않는 Connect By가 유리하다.
결국 각 기능들의 허와 실을 제대로 파악하고 성능 이슈를 최소화 한다면 모두가 웃을 수 있을 것이다.
모두가 웃는 그날까지......