대용량 Parallel 쿼리 에서 조인을 사용할 경우 성능이 저하되는 경우가 많이 있다.
이경우의 원인은 여러가지가 있다.
원인 중에서 가장 치명적인 것은 잘못된 Row Distribution (Row 의 분배방법) 에 있다.
옵티마이져의 잘못된 Row Distribution 을 피하기 위하여 원리및 사용방법 그리고 최후의 방법으로 힌트를 통한 잘못된 Row Distribution 을 피하기 등에 대하여 알아본다.
필자가 이주제를 선택한 이유는 예전에 필자가 그랬듯이 이해하기가 힘들고 DBA 및 튜너라고 할지라도 모르는 사람들이 많이 있기 때문이다.
그렇기 때문에 최대한 이해하기 쉽게 설명 하였다.
1. Row Distribution Method
Parallel 옵션을 사용한 Select 에서 조인시에 Row 의 분배방법에는 4 가지가 있다.
한가지씩 알아보자
조인컬럼 기준으로 각각의 Temp 성 매핑테이블을 만들고 마지막에 Join 하는 방식이다.
2).Broadcast : 조인된 양쪽테이블에서 한쪽 테이블의 모든 Row를 다른쪽 테이블을 Scan 시에
분배하는 방식이다.
BroadCast 받는 Table의 Scan 시에 자동으로 조인이 되므로 따로 Join Operation 이
필요가 없다.
하지만 Broadcast 하는측 테이블의 사이즈가 커지면 Parallel Slave 마다 Outer Table 을
반복적으로 BroadCast 해야 하므로 비효율이 커진다.
3).Partition : 파티션을 이용하여 조인이된 양쪽테이블의 Row 를 분배한다.
2개의 조인된 테이블 중에서 조인컬럼을 기준으로 반드시 한쪽 테이블은 파티션이
되어 있어야한다.
파티션이 안된 테이블을 조인컬럼을 기준으로 파티션하여 Row 를 분배하는 방식이다.
이분배방식은 Partition Wise Join 과 관계가 있다.
4).None : 이미 조인컬럼기준으로 파티션 된 테이블은 Row 가 파티션기준으로 자동으로 분배되거나
Broadcast 방식일 경우 분배를 받는쪽 테이블의 Row 는 따로 분배가 필요 없으므로
None 으로 표현된다.
2.조인시 Row Distribution 의 Combination
한테이블의 Row 분배방식을 알았으니 이젠 양측 테이블의 Row 분배를 조인을 위하여 결합해야 하는데
4지 분배방식 중에서 Oracle 에서 허용되는 Combination 은 아래처럼 6가지 이다.
보는 방법은 Comma( , ) 왼쪽이 Outer Table 오른쪽이 Inner Table 이다.
다시말하면 조인이 왼쪽테이블에서 오른쪽 테이블로 진행된다.
2) BROADCAST, NONE : Outer Table 의 사이즈와 Inner Table 의 사이즈를 비교하여 Outer 테이블의
사이즈가 훨씬적을때 권장된다.
예를들면 코드 테이블과 대용량 테이블을 조인할때 적격이다.
왜냐하면 Inner Table 의 Granule 갯수 만큼 Outer 테이블의 Row 가 반복해서
제공되어야 하기 때문에 Broadcast 하는쪽의 테이블이 크면 I/O 양이 급격히
늘어난다.
3) NONE, BROADCAST : 2) 번의 방법과 같으나 순서가 정반대 이다.
다시말해 Inner 테이블이 Broadcast 된다.
Outer Table 의 사이즈와 Inner Table 의 사이즈를 비교하여 Inner 테이블의
사이즈가 훨씬적을때 권장된다.
--> Outer 가 Driving 되는 Hash Join 을 사용시 최악의 Combination 임.
4) PARTITION, NONE : Outer 테이블을 조인된 컬럼기준으로 Partition을 하여 Row 를 분배하며
Partition Wise 조인을 한다.
5) NONE, PARTITION : Inner 테이블을 조인된 컬럼기준으로 Partition을 하여 Row 를 분배하며
Partition Wise 조인을 한다.
6) NONE, NONE : 조인이되는 양측의 테이블이 이미 조인컬럼 기준으로 파티션이 되어 있을때 따로 분배가
필요없으므로 이런 Combination 이 발생한다.(양측 테이블이 파티션 기준으로 분배된다.)
3. PQ_DISTRIBUTE 힌트의 사용
다시한번 말하지만 파티션 분배방식을 제외하면 양측 테이블의 Size 가 비슷한 경우는 분배방식은 Hash, Hash 로 풀려야 하고 코드성 테이블과 같이 소형 테이블과 대형테이블의 조인인경우는 Broadcast, None 으로 풀려야 한다.
그럼에도 불구하고 Optimizer 가 잘못된 분배방식의 Combination 을 선택하였다면 10중 8, 9 는 통계정보를 제대로 생성해주면 된다.
왜냐하면 파티션 분배방식을 제외하고 Broadcast 나 Hash 등의 분배방식을 선택할떄 Row 수 및 평균 Row 의 길이 등이 결정적인 영향을 끼치기 때문이다.
하지만 Temp 성 테이블이나 Global temp Table 등을 사용하면 통계정보가 아예 없다.
또한 통계정보가 있어도 Optimizer 잘못된선택을 할수도 있다.
이때 사용할수 있는 힌트중의 하나가 PQ_DISTRIBUE 이다.
아래의 힌트 옵션을 보고 실제 SQL 을 살펴보자.
위의 힌트에서 보듯이 Inner 테이블명이나 Alias 를 먼저적고 Row 분배방식의 Combination 을 작성하면 된다.
예제1)
FROM r,s
WHERE r.c=s.c;
예제1) 은 Outer Table(R) 과 Inner Table(S) 의 SIZE 가 비슷하므로 각각 Hash 분배방식으로 힌트를 사용하였다.
예제2)
FROM a,b
WHERE a.c = b.c;
예제2)는 Outer Table(a) 가 Inner Table(b) 보다 훨씬 적으므로 BROADCAST, NONE 방식을 취하도록 힌트를 사용하였다.
다시말하면 b 테이블 scan 시에 발생하는 Parallel 의 각각의 Slave 마다 Brodcast 된 a 테이블과의 조인을 동시에 하겠다는 뜻이다.
예제3)
ALTER TABLE dept2 PARALLEL 2;
CREATE TABLE emp_comp PARTITION BY RANGE(hire_date)
SUBPARTITION BY HASH(department_id) SUBPARTITIONS 3
(
PARTITION emp_p1 VALUES LESS THAN (TO_DATE(’1-JAN-1992’,’DD-MON-YYYY’)),
PARTITION emp_p2 VALUES LESS THAN (TO_DATE(’1-JAN-1994’,’DD-MON-YYYY’)),
PARTITION emp_p3 VALUES LESS THAN (TO_DATE(’1-JAN-1996’,’DD-MON-YYYY’)),
PARTITION emp_p4 VALUES LESS THAN (TO_DATE(’1-JAN-1998’,’DD-MON-YYYY’)),
PARTITION emp_p5 VALUES LESS THAN (TO_DATE(’1-JAN-2001’,’DD-MON-YYYY’))
)
AS SELECT * FROM employees;
ALTER TABLE emp_comp PARALLEL 2;
EXPLAIN PLAN FOR
SELECT /*+ PQ_DISTRIBUTE(d NONE PARTITION) ORDERED */ e.last_name,
--> dept2 를 department_id 로 dynamic 파티션을 하여 row 를 분배하겠다는 의미임.
d.department_name
FROM emp_comp e, dept2 d
WHERE e.department_id = d.department_id;
SELECT PLAN_TABLE_OUTPUT FROM TABLE(DBMS_XPLAN.DISPLAY());
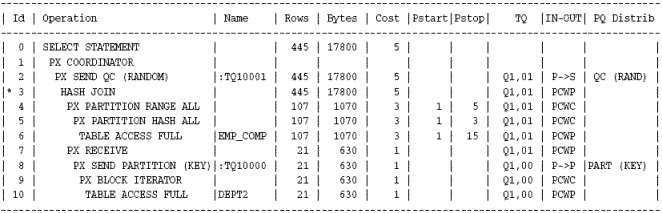
예제3)은 dept2 테이블을 조인기준컬럼인 department_id 로 Dynamic Partition 하여 ROW 를 분배한다.
dept2 테이블은 파티션이 되어 있지않으므로 Partial Partioin Wise Join 이 발생 하였다.
Plan 상의 분배방식도 힌트에서 의도한대로 Part(key) 로 나타났다
예제4)
PARTITION BY HASH(department_id)
PARTITIONS 3
PARALLEL 2
AS SELECT * FROM departments;
EXPLAIN PLAN FOR
SELECT /*+ PQ_DISTRIBUTE(e NONE NONE) ORDERED */ e.last_name,
--> 이미 양측 테이블이 파티션이 되어있으므로 분배방식이 따로 필요가 없으나
(Hash, hash) 나 (broadcast, none) 등으로 풀리는 것을 방지하는 차원에서 힌트를 사용함.
d.department_name
FROM emp_comp e, dept_hash d
WHERE e.department_id = d.department_id;
SELECT PLAN_TABLE_OUTPUT FROM TABLE(DBMS_XPLAN.DISPLAY());
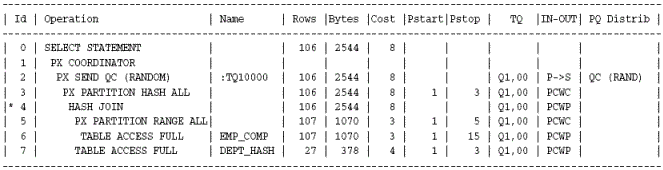
예제4)는 양측 테이블이 모두 조인기준컬럼으로 파티션 되어 있기 때문에 Full Partition Wise Join 되었으며 분배방식에도 아무것도 나타나지 않았다( 아무것도 나타나지 않으면 None 임)
당연한 이야기 이지만 emp_comp 테이블의 department_id 컬럼은 Sub Partiotion 이다.
Sub Partiion 도 위의 Plan 처럼 Full Partition Wise Join 이 가능하다.
4.결론
Row 분배방식, 분배방식의 Combination , Optimizer 가 잘못된 분배방식을 선택할 경우를 위한 PQ_DISTRIBUTE 힌트의 사용등을 알아보았다.
잘못된 Row Distribution 을 피하기 위한 목적 뿐만 아니라 Parallel Operation 을 이해하기 위해서는 반드시 알야야 하니 다시한번 꼼꼼히 살펴보기 바란다.
'Oracle > Data Join Method' 카테고리의 다른 글
| Hash 조인의 튜닝시 주의사항(Work Area 의 튜닝) (3) | 2008.10.30 |
|---|---|
| Parallel Query 의 조인시 또다른 튜닝방법(Parallel Join Filter) (6) | 2008.10.12 |
| New Features 의 중요성(Partition Outer Join 의 사용법) (5) | 2008.08.29 |
| Lateral View 를 활용한 선택적 조인 (2) | 2008.05.29 |
| Outer Join 의 재조명 (2) | 2008.04.07 |





