부제: Partition Wise Join의 성능
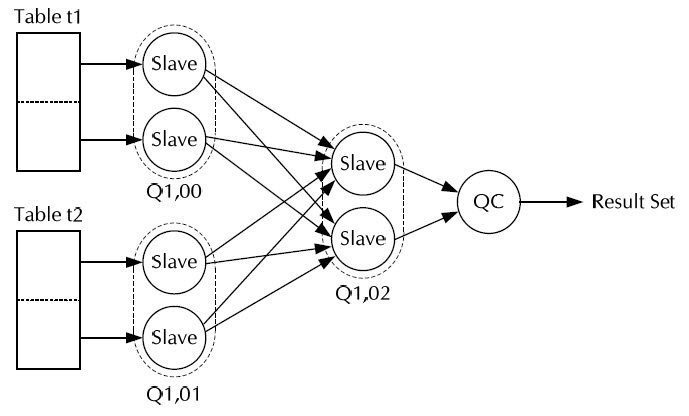
DBA나 튜닝 컨설턴트들에게 PARTITION WISE JOIN(이후 PWJ)를 설명해 보라고 하면, 언제나 PARALLEL과 PQ_DISTRIBUTE 힌트를 언급한다. 이상한 일이다. PWJ는 PARALLEL + PQ_DISTRIBUTE 힌트 조합과 상관없이 독립적으로 존재한다. 그럼에도 불구하고 PWJ를 설명하기 위해 두 힌트를 항상 끌어들인다. 마치 PWJ 기능이 두 힌트에 종속되기라도 하는 것처럼 말이다. 그 이유는 메뉴얼을 포함한 거의 모든 튜닝책에 위의 두 힌트를 사용해서 PWJ를 설명하고 있기 때문이다.
말도 안 되는 소리
이제는 PWJ를 설명 할 때, PARALLEL과 PQ_DISTRIBUTE 힌트와 연계하여 설명하지 말기 바란다. 이렇게 연계하여 설명하는 것은 근본원리를 모르면서 활용하려고 하는 것이다. 더 잘못된 것은 성능이 개선되는 이유는 조인할 PARTITION을 미리 짝지어 놓았기 때문(Partition Pair)에 조인이 빠르다고 설명한다. 잘못된 설명이다. 성능문제의 대부분이 두 가지 관점(BLOCK I/O와 PGA 사용량)으로 결정된다는 것은 상식이다. 그런데 두 가지 관점을 설명하지도 않고 PARTITION을 미리 짝지어 놓았기 때문에 빠르다는 것은 어불성설이다.
지금까지의 PWJ의 정의를 과감히 버려라. 그리고 지금부터 PWJ를 재정의 해보자. PWJ를 다시 설명하지 않으면 다음의 세가지를 알 수 없다.
1. PARALLEL 힌트와 PQ_DISTRIBUTE 힌트를 사용하지 않고 PWJ를 설명 할 수 있다.
2. PWJ를 사용함으로써 개선된 성능을 BLOCK I/O로 나타낼 수 있다.
3. PWJ를 사용함으로써 개선된 성능을 PGA 사용량으로 나타낼 수 있다.
1. 번은 개념을 설명하는 것이다. 2,3번은 성능향상을 수치로 나타낼 수 있느냐는 것이다. 아마 기존의 상식으로는 힘들것이다. 따라서 이글의 목적은 위의 세 가지를 이해하고 나타낼 수 있는 능력을 기르는 것이다.
먼저 파티션 테이블 두 개(SALES_PT,SALES_ORDER_PT)를 만들고, 파티션이 되지 않은 테이블 두 개(SALES_NO_PT, SALES_ORDER_NO_PT)를 만든다. SALES_PT와 SALES_NO_PT의 차이점은 전자는 파티셔닝이 적용되고 후자는 적용되지 않았다는 것이다. SALES_ORDER_PT와 SALES_ORDER_NO_PT의 차이점도 마찬가지다.
테이블 생성 스크립트 다운로드
 Table Generation.SQL
Table Generation.SQL환경: 오라클 11.2.0.1
모든 테이블은 대략 92만 건이다.
SALES_PT, SALES_ORDER_PT 두 테이블의 파티션 키 컬럼은 TIME_ID 이다.
먼저 파티션이 되지 않은 테이블 두 개를 이용하여 HASH JOIN으로 실행해보자.
SELECT /*+ LEADING(T) */ COUNT(*)
FROM SALES_NO_PT S, SALES_ORDER_NO_PT T
WHERE T.ORDER_DT = TO_DATE('20010101', 'YYYYMMDD')
AND S.PROD_ID = T.PROD_ID
AND S.CUST_ID = T.CUST_ID
AND S.TIME_ID = T.TIME_ID
AND S.CHANNEL_ID = S.CHANNEL_ID
AND S.PROMO_ID = T.PROMO_ID ;
------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | A-Rows | A-Time | Buffers |
------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 1 |00:00:05.20 | 9898 |
| 1 | SORT AGGREGATE | | 1 | 1 |00:00:05.20 | 9898 |
|* 2 | HASH JOIN | | 1 | 154 |00:00:05.20 | 9898 |
|* 3 | TABLE ACCESS FULL| SALES_ORDER_NO_PT | 1 | 88 |00:00:03.12 | 5457 |
| 4 | TABLE ACCESS FULL| SALES_NO_PT | 1 | 918K|00:00:01.20 | 4441 |
------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("S"."PROD_ID"="T"."PROD_ID" AND "S"."CUST_ID"="T"."CUST_ID" AND "S"."TIME_ID"="T"."TIME_ID" AND
"S"."PROMO_ID"="T"."PROMO_ID")
3 - filter("T"."ORDER_DT"=TO_DATE(' 2001-01-01 00:00:00', 'syyyy-mm-dd hh24:mi:ss'))
파티션이 아님으로 PWJ가 발생하지 않았다. ID 4의 BLOCK I/O(Buffers)가 4441임을 주목하라. 또한 후행테이블의 건수(A-Row)가 918K임을 기억하라. 이제 PWJ 를 실행할 차례다.
SELECT /*+ LEADING(T) */ COUNT(*)
FROM SALES_PT S, SALES_ORDER_PT T
WHERE T.ORDER_DT = TO_DATE('20010101', 'YYYYMMDD')
AND S.PROD_ID = T.PROD_ID
AND S.CUST_ID = T.CUST_ID
AND S.TIME_ID = T.TIME_ID
AND S.CHANNEL_ID = S.CHANNEL_ID
AND S.PROMO_ID = T.PROMO_ID ;
--------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | Pstart| Pstop | A-Rows | A-Time | Buffers |
--------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | | 1 |00:00:00.18 | 6263 |
| 1 | SORT AGGREGATE | | 1 | | | 1 |00:00:00.18 | 6263 |
| 2 | PARTITION RANGE ALL| | 1 | 1 | 28 | 154 |00:00:00.18 | 6263 |
|* 3 | HASH JOIN | | 28 | | | 154 |00:00:00.18 | 6263 |
|* 4 | TABLE ACCESS FULL| SALES_ORDER_PT | 28 | 1 | 28 | 88 |00:00:00.10 | 5947 |
| 5 | TABLE ACCESS FULL| SALES_PT | 1 | 1 | 28 | 60608 |00:00:00.02 | 316 |
--------------------------------------------------------------------------------------------------------
Outline Data
-------------
/*+
BEGIN_OUTLINE_DATA
...생략
PX_JOIN_FILTER(@"SEL$1" "S"@"SEL$1")
END_OUTLINE_DATA
*/
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("S"."TIME_ID"="T"."TIME_ID" AND "S"."PROD_ID"="T"."PROD_ID" AND "S"."CUST_ID"="T"."CUST_ID" AND
"S"."PROMO_ID"="T"."PROMO_ID")
4 - filter("T"."ORDER_DT"=TO_DATE(' 2001-01-01 00:00:00', 'syyyy-mm-dd hh24:mi:ss'))
조인된 두 테이블은 모두 파티셔닝 되었다. 따라서 PARTITION RANGE ALL이 두 번 나와야 됨에도 불구하고 ID 2을 보면 단 한번만 나온다. PWJ가 실행되었다는 증거다. PWJ가 실행되지 않은 경우와 BLOCK I/O를 비교해 보면 14배 이상 차이가 난다. 바로 이 것이 FULL PWJ가 실행되면 성능에 유리한 이유다. FULL PWJ가 실행되면 후행 테이블의 파티션을 모두 읽을 필요가 없다. 왜냐하면 이미 선행테이블(BUILD INPUT)을 읽는 과정에서 어떤 파티션을 액세스 할 것인지 결정 되었기 때문이다. 따라서 후행테이블의 건수도 918K건이 아니라 59K건(60608건)에 불과한 것이다.
위의 Outline Data를 보고 혹자는 'PX_JOIN_FILTER 때문에 PARTITION PRUNING이 일어난 것이다' 고 의혹을 제기한다. 하지만 PX_JOIN_FILTER는 FULL PWJ는 아무 상관이 없다. 왜냐하면 아래와 같이 NO_PX_JOIN_FILTER 힌트를 사용해서 Filter를 제거해도 PWJ의 효과가 유지되기 때문이다.
SELECT /*+ LEADING(T) NO_PX_JOIN_FILTER(S) */ COUNT(*)
FROM SALES_PT S, SALES_ORDER_PT T
WHERE T.ORDER_DT = TO_DATE('20010101', 'YYYYMMDD')
AND S.PROD_ID = T.PROD_ID
AND S.CUST_ID = T.CUST_ID
AND S.TIME_ID = T.TIME_ID
AND S.CHANNEL_ID = S.CHANNEL_ID
AND S.PROMO_ID = T.PROMO_ID ;
--------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | Pstart| Pstop | A-Rows | A-Time | Buffers |
--------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | | 1 |00:00:00.18 | 6263 |
| 1 | SORT AGGREGATE | | 1 | | | 1 |00:00:00.18 | 6263 |
| 2 | PARTITION RANGE ALL| | 1 | 1 | 28 | 154 |00:00:00.18 | 6263 |
|* 3 | HASH JOIN | | 28 | | | 154 |00:00:00.18 | 6263 |
|* 4 | TABLE ACCESS FULL| SALES_ORDER_PT | 28 | 1 | 28 | 88 |00:00:00.10 | 5947 |
| 5 | TABLE ACCESS FULL| SALES_PT | 1 | 1 | 28 | 60608 |00:00:00.02 | 316 |
--------------------------------------------------------------------------------------------------------
Outline Data
-------------
/*+
BEGIN_OUTLINE_DATA
IGNORE_OPTIM_EMBEDDED_HINTS
OPTIMIZER_FEATURES_ENABLE('11.2.0.1')
DB_VERSION('11.2.0.1')
ALL_ROWS
OUTLINE_LEAF(@"SEL$1")
FULL(@"SEL$1" "T"@"SEL$1")
FULL(@"SEL$1" "S"@"SEL$1")
LEADING(@"SEL$1" "T"@"SEL$1" "S"@"SEL$1")
USE_HASH(@"SEL$1" "S"@"SEL$1")
END_OUTLINE_DATA
*/
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("S"."TIME_ID"="T"."TIME_ID" AND "S"."PROD_ID"="T"."PROD_ID" AND "S"."CUST_ID"="T"."CUST_ID"
AND "S"."PROMO_ID"="T"."PROMO_ID")
4 - filter("T"."ORDER_DT"=TO_DATE(' 2001-01-01 00:00:00', 'syyyy-mm-dd hh24:mi:ss'))
위의 SQL에서 NO_PX_JOIN_FILTER를 사용하여 FILTER를 제거시켰지만 여전히 PWJ가 실행되었다. 따라서 PX_JOIN_FILTER도 FULL PWJ의 원리가 아니다. PWJ의 성능향상 원리는 T.ORDER_DT = TO_DATE('20010101', 'YYYYMMDD') 조건에 있다. 다시 말해 이 조건 때문에 후행 테이블은 2001년도 1분기 파티션만 읽으면 되는 것이다. 중요한 점은 T.ORDER_DT 컬럼이 Partition Key 컬럼이 아님에도 성능이 향상되었다는 점이다. 아래의 SQL이 그것을 증명한다.
SELECT /*+ FULL(SALES) */ COUNT(*)
FROM SALES_PT PARTITION (ST_Q1_2001);
-----------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | Pstart| Pstop | A-Rows | A-Time | Buffers |
-----------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | | 1 |00:00:00.05 | 316 |
| 1 | SORT AGGREGATE | | 1 | | | 1 |00:00:00.05 | 316 |
| 2 | PARTITION RANGE SINGLE| | 1 | 17 | 17 | 60608 |00:00:00.04 | 316 |
| 3 | TABLE ACCESS FULL | SALES_PT | 1 | 17 | 17 | 60608 |00:00:00.02 | 316 |
-----------------------------------------------------------------------------------------------------
PWJ의 성능개선 원리는 선행집합의 Filter에 있다
FULL PWJ가 발생했을 때와 같이 정확히 316 BLOCK 만 읽었다. PWJ가 실행됨으로써 BLOCK I/O 관점의 성능개선사항은 명확해졌다. 선행집합의 FILTER가 후행집합의 BLOCK I/O를 결정한다는 것이다. 다시 말해 선행집합은 T.ORDER_DT = 상수조건에 상관없이 모든 파티션을 ACCESS 해야 한다. 하지만 후행집합은 T.ORDER_DT = 상수조건에 만족하는 파티션만 ACCESS 하는 것이 PWJ의 성능개선 원리이다.
Partial PWJ의 성능개선 원리도 FULL PWJ와 같다
FULL PWJ의 성능개선 원리와 Partial PWJ의 성능개선 원리는 같다. 하지만 처리방식이 다르다. Partial PWJ는 내부적으로Bloom Pruning을 이용한다. Bloom Filter를 이용하여 후행테이블의 조인건수를 줄일 수 있는데, Bloom Pruning도 같은 메커니즘을 이용하여 후행 테이블의 파티션 Access 개수를 최소화 하는 것이다. 아래의 SQL은 Partial PWJ 예제이며, Bloom Pruning을 이용하여 후행집합의 파티션 Access 개수를 최소화 하고 있다.
ALTER SESSION SET "_bloom_pruning_enabled" = TRUE;
SELECT /*+ LEADING(T) USE_HASH(S) */ COUNT(*)
FROM SALES_PT S, SALES_ORDER_NO_PT T
WHERE T.ORDER_DT = TO_DATE('20010101', 'YYYYMMDD')
AND S.PROD_ID = T.PROD_ID
AND S.CUST_ID = T.CUST_ID
AND S.TIME_ID = T.TIME_ID
AND S.CHANNEL_ID = S.CHANNEL_ID
AND S.PROMO_ID = T.PROMO_ID ;
---------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts| Pstart| Pstop | A-Rows| A-Time | Buffers|
---------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1| | | 1|00:00:00.64| 5773|
| 1 | SORT AGGREGATE | | 1| | | 1|00:00:00.64| 5773|
|* 2 | HASH JOIN | | 1| | | 154|00:00:00.64| 5773|
| 3 | PART JOIN FILTER CREATE | :BF0000 | 1| | | 88|00:00:00.52| 5457|
|* 4 | TABLE ACCESS FULL | SALES_ORDER_NO_PT| 1| | | 88|00:00:00.52| 5457|
| 5 | PARTITION RANGE JOIN-FILTER| | 1|:BF0000|:BF0000| 60608|00:00:00.05| 316|
| 6 | TABLE ACCESS FULL | SALES_PT | 1|:BF0000|:BF0000| 60608|00:00:00.03| 316|
---------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("S"."TIME_ID"="T"."TIME_ID" AND "S"."PROD_ID"="T"."PROD_ID"
AND "S"."CUST_ID"="T"."CUST_ID" AND "S"."PROMO_ID"="T"."PROMO_ID")
4 - filter("T"."ORDER_DT"=TO_DATE(' 2001-01-01 00:00:00', 'syyyy-mm-dd hh24:mi:ss'))
FULL PARTITION WISE JOIN과 PARTIAL PARTITION WISE JOIN의 성능개선 원리는 같으며, BLOCK I/O도 동일하다. 다른 점은 PARTIAL PARTITION WISE JOIN이 Bloom Pruning를 이용했다는 것뿐이다. 다시 말해, 아래처럼 Bloom Pruning 기능을 사용할 수 없게 된다면 PARTIAL PARTITION WISE JOIN시 성능향상(후행 집합의 BLOCK I/O 감소)을 기대할 수 없다.
ALTER SESSION SET "_bloom_pruning_enabled" = false;
SELECT /*+ LEADING(T) USE_HASH(S) */ COUNT(*)
FROM SALES_PT S, SALES_ORDER_NO_PT T
WHERE T.ORDER_DT = TO_DATE('20010101', 'YYYYMMDD')
AND S.PROD_ID = T.PROD_ID
AND S.CUST_ID = T.CUST_ID
AND S.TIME_ID = T.TIME_ID
AND S.CHANNEL_ID = S.CHANNEL_ID
AND S.PROMO_ID = T.PROMO_ID ;
------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | Pstart| Pstop | A-Rows | A-Time | Buffers |
------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | | 1 |00:00:01.22 | 10341 |
| 1 | SORT AGGREGATE | | 1 | | | 1 |00:00:01.22 | 10341 |
|* 2 | HASH JOIN | | 1 | | | 154 |00:00:01.22 | 10341 |
|* 3 | TABLE ACCESS FULL | SALES_ORDER_NO_PT | 1 | | | 88 |00:00:00.54 | 5457 |
| 4 | PARTITION RANGE ALL| | 1 | 1 | 28 | 918K|00:00:00.31 | 4884 |
| 5 | TABLE ACCESS FULL | SALES_PT | 28 | 1 | 28 | 918K|00:00:00.15 | 4884 |
------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("S"."PROD_ID"="T"."PROD_ID" AND "S"."CUST_ID"="T"."CUST_ID" AND "S"."TIME_ID"="T"."TIME_ID" AND
"S"."PROMO_ID"="T"."PROMO_ID")
3 - filter("T"."ORDER_DT"=TO_DATE(' 2001-01-01 00:00:00', 'syyyy-mm-dd hh24:mi:ss'))
_bloom_pruning_enabled 파라미터를 false로 놓고 실행하자 SALES_PT 테이블의 모든 파티션을 Access하게 되었다. 이에 따라 성능도 저하된다. PARTIAL PARTITION WISE JOIN이 Bloom Pruning를 이용하고 있다는 증거이다.
Partition Pair는 PWJ의 성능개선 원리가 아니다
많은 책에서 PWJ를 설명하기 위해 Partition Pair라는 용어를 사용하고 있다. 하지만 Partition Pair는 PWJ의 원리가 아니라, 조인 시 선행집합에 PARTITION PRUNING이 발생한 것뿐이다. 아래의 SQL을 실행시켜 보자.
SELECT /*+ LEADING(T) */ COUNT(*)
FROM SALES_PT S, SALES_ORDER_PT T
WHERE T.ORDER_DT = TO_DATE('20010101', 'YYYYMMDD')
AND T.TIME_ID BETWEEN TO_DATE('20010101', 'YYYYMMDD') AND TO_DATE('20011231', 'YYYYMMDD')
AND S.PROD_ID = T.PROD_ID
AND S.CUST_ID = T.CUST_ID
AND S.TIME_ID = T.TIME_ID
AND S.CHANNEL_ID = S.CHANNEL_ID
AND S.PROMO_ID = T.PROMO_ID ;
-------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | Pstart| Pstop | A-Rows | A-Time | Buffers |
-------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | | 1 |00:00:00.08 | 1984 |
| 1 | SORT AGGREGATE | | 1 | | | 1 |00:00:00.08 | 1984 |
| 2 | PARTITION RANGE ITERATOR| | 1 | 17 | 20 | 154 |00:00:00.08 | 1984 |
|* 3 | HASH JOIN | | 4 | | | 154 |00:00:00.08 | 1984 |
|* 4 | TABLE ACCESS FULL | SALES_ORDER_PT | 4 | 17 | 20 | 88 |00:00:00.02 | 1668 |
|* 5 | TABLE ACCESS FULL | SALES_PT | 1 | 17 | 20 | 60608 |00:00:00.02 | 316 |
-------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("S"."TIME_ID"="T"."TIME_ID" AND "S"."PROD_ID"="T"."PROD_ID" AND "S"."CUST_ID"="T"."CUST_ID" AND
"S"."PROMO_ID"="T"."PROMO_ID")
4 - filter(("T"."ORDER_DT"=TO_DATE(' 2001-01-01 00:00:00', 'syyyy-mm-dd hh24:mi:ss')
AND "T"."TIME_ID"<=TO_DATE(' 2001-12-31 00:00:00', 'syyyy-mm-dd hh24:mi:ss')))
5 - filter("S"."TIME_ID"<=TO_DATE(' 2001-12-31 00:00:00', 'syyyy-mm-dd hh24:mi:ss'))
T.TIME_ID 조건에 의해서 선행집합에 PARTITION PRUNING이 발생하여 전체 파티션이 아닌 2001년도 파티션 4개만 읽으면 된다. 이에 따라 선행 테이블의 I/O가 5947에서 1668로 줄어들었다. 비록 선행집합의 I/O가 줄어들었지만, PWJ의 성능 개선 원리인 '선행집합의 FILTER 조건이 후행집합의 BLOCK I/O를 결정한다'는 변치 않는다. 즉 선행테이블의 두 조건인 T.ORDER_DT = 조건과 T.TIME_ID BETWEEN 조건의 교집합이 후행테이블의 ACCESS 범위가 되는 것이다. 만약 PWJ의 성능개선 원리가 없고 Partition Pair만 존재했다면 후행집합이 2001년에 해당하는 파티션 4개를 모두 읽어야 할 것이다. 하지만 위에서 보는 것처럼 후행집합은 단 하나의 파티션만 Access 한다.
물론 아무런 조건 없이 Partition Key 조건만 있다면 아래처럼 Partition Pair가 되기는 한다.
SELECT /*+ LEADING(T) USE_HASH(S) */ COUNT(*)
FROM SALES_PT S, SALES_ORDER_PT T
WHERE T.TIME_ID BETWEEN TO_DATE('20010101', 'YYYYMMDD') AND TO_DATE('20011231', 'YYYYMMDD')
AND S.PROD_ID = T.PROD_ID
AND S.CUST_ID = T.CUST_ID
AND S.TIME_ID = T.TIME_ID
AND S.CHANNEL_ID = S.CHANNEL_ID
AND S.PROMO_ID = T.PROMO_ID ;
-------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | Pstart| Pstop | A-Rows | A-Time | Buffers |
-------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | | 1 |00:00:00.61 | 3022 |
| 1 | SORT AGGREGATE | | 1 | | | 1 |00:00:00.61 | 3022 |
| 2 | PARTITION RANGE ITERATOR| | 1 | 17 | 20 | 464K|00:00:00.58 | 3022 |
|* 3 | HASH JOIN | | 4 | | | 464K|00:00:00.50 | 3022 |
|* 4 | TABLE ACCESS FULL | SALES_ORDER_PT | 4 | 17 | 20 | 259K|00:00:00.05 | 1668 |
|* 5 | TABLE ACCESS FULL | SALES_PT | 4 | 17 | 20 | 259K|00:00:00.05 | 1354 |
-------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("S"."TIME_ID"="T"."TIME_ID" AND "S"."PROD_ID"="T"."PROD_ID" AND "S"."CUST_ID"="T"."CUST_ID" AND
"S"."PROMO_ID"="T"."PROMO_ID")
4 - filter("T"."TIME_ID"<=TO_DATE(' 2001-12-31 00:00:00', 'syyyy-mm-dd hh24:mi:ss'))
5 - filter("S"."TIME_ID"<=TO_DATE(' 2001-12-31 00:00:00', 'syyyy-mm-dd hh24:mi:ss'))
T.ORDER_DT 조건을 삭제하고 T.TIME_ID 조건만 있으므로 정확히 두 테이블은 Pair이다. 즉 두 테이블은 2001년 파티션을 각각 4개씩 읽었다. 즉 PWJ 발생시 BLOCK I/O 관점의 성능개선 원리는 FULL PWJ이냐 아니면 Partial PWJ이냐에 따라 변치 않으며 아래처럼 정의 할 수 있다.
1. 선행집합의 파티션 ACCESS 범위는 PARTITION KEY 조건에 의한 Partition Pruning에 의해 결정된다. 하지만 이 기능은 PWJ의 장점이 아니다. 왜냐하면 조인이 아닌 경우도 실행되기 때문이다.
2. 후행집합의 파티션 ACCESS 범위는 선행집합의 모든 FILTER에 의해 결정된다. 이 기능이야 말로 Partition Wise Join의 장점이다. 왜냐하면 조인에 의해서 성능이 향상되기 때문이다.
이
PWJ 성능향상의 두 번째 원리
이제 BLOCK I/O관점에서 성능개선 원리가 밝혀졌으므로, PGA 사용량 관점에서 PWJ의 성능개선 원리를 나타내 보자.
SELECT /*+ LEADING(T) */ COUNT(*)
FROM SALES_NO_PT S, SALES_ORDER_NO_PT T
WHERE S.PROD_ID = T.PROD_ID
AND S.CUST_ID = T.CUST_ID
AND S.TIME_ID = T.TIME_ID
AND S.CHANNEL_ID = S.CHANNEL_ID
AND S.PROMO_ID = T.PROMO_ID ;
-----------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | A-Rows | A-Time | Buffers | Used-Mem |
-----------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 1 |00:00:04.22 | 9898 | |
| 1 | SORT AGGREGATE | | 1 | 1 |00:00:04.22 | 9898 | |
|* 2 | HASH JOIN | | 1 | 1418K|00:00:04.00 | 9898 | 54M (0)|
| 3 | TABLE ACCESS FULL| SALES_ORDER_NO_PT | 1 | 918K|00:00:00.40 | 5457 | |
| 4 | TABLE ACCESS FULL| SALES_NO_PT | 1 | 918K|00:00:00.36 | 4441 | |
-----------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("S"."PROD_ID"="T"."PROD_ID" AND "S"."CUST_ID"="T"."CUST_ID"
AND "S"."TIME_ID"="T"."TIME_ID" AND "S"."PROMO_ID"="T"."PROMO_ID")
PWJ가 실행되지 않는 경우 PGA를 54MB나 소모하였다. 이제 PWJ를 실행시켜 성능이 얼마나 개선되는지 알아보자.
SELECT /*+ LEADING(T) */ COUNT(*)
FROM SALES_PT S, SALES_ORDER_PT T
WHERE S.PROD_ID = T.PROD_ID
AND S.CUST_ID = T.CUST_ID
AND S.TIME_ID = T.TIME_ID
AND S.CHANNEL_ID = S.CHANNEL_ID
AND S.PROMO_ID = T.PROMO_ID ;
--------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | Pstart| Pstop| A-Rows | A-Time | Buffers|Used-Mem |
---------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | | 1 |00:00:04.48| 10795| |
| 1 | SORT AGGREGATE | | 1 | | | 1 |00:00:04.48| 10795| |
| 2 | PARTITION RANGE ALL| | 1 | 1 | 28| 1418K|00:00:04.26| 10795| |
|* 3 | HASH JOIN | | 28 | | | 1418K|00:00:03.69| 10795|5008K (0)|
| 4 | TABLE ACCESS FULL| SALES_ORDER_PT | 28 | 1 | 28| 918K|00:00:00.34| 5947| |
| 5 | TABLE ACCESS FULL| SALES_PT | 16 | 1 | 28| 918K|00:00:00.34| 4848| |
---------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("S"."TIME_ID"="T"."TIME_ID" AND "S"."PROD_ID"="T"."PROD_ID"
AND "S"."CUST_ID"="T"."CUST_ID" AND "S"."PROMO_ID"="T"."PROMO_ID")
PWJ를 실행하니 PGA 사용량이 11배나 줄어들었다. PWJ란 덩치가 큰 테이블 두 개를 조인시켜야 될 때, 작은 여러 개의 파티션으로 쪼개서 각각 조인시킴으로써 조인의 성능을 향상 시키는 것이다. 이렇게 되면 당연히 PGA 사용량이 급격히 줄어들 것이다.
한가지 주의 사항이 있다. PWJ가 발생하려면 파티션 기준 컬럼으로 양측 집합을 조인해야 한다. 그런데 파티션 Key 조인 컬럼을 아래처럼 가공하게 되면 PWJ가 발생되지 않으므로 주의하기 바란다
SELECT /*+ LEADING(T) */ COUNT(*)
FROM SALES_PT S, SALES_ORDER_PT T
WHERE T.ORDER_DT = TO_DATE('20010101', 'YYYYMMDD')
AND S.PROD_ID = T.PROD_ID
AND S.CUST_ID = T.CUST_ID
AND S.TIME_ID + 1 = T.TIME_ID + 1 --파티션 기준컬럼 가공
AND S.CHANNEL_ID = S.CHANNEL_ID
AND S.PROMO_ID = T.PROMO_ID ;
---------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts| Pstart| Pstop|A-Rows | A-Time |Buffers |Used-Mem |
---------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1| | | 1 |00:00:02.23 | 10831 | |
| 1 | SORT AGGREGATE | | 1| | | 1 |00:00:02.23 | 10831 | |
|* 2 | HASH JOIN | | 1| | | 154 |00:00:02.23 | 10831 |1210K (0)|
| 3 | PARTITION RANGE ALL| | 1| 1 | 28| 88 |00:00:00.10 | 5947 | |
|* 4 | TABLE ACCESS FULL | SALES_ORDER_PT | 28| 1 | 28| 88 |00:00:00.10 | 5947 | |
| 5 | PARTITION RANGE ALL| | 1| 1 | 28| 918K|00:00:00.70 | 4884 | |
| 6 | TABLE ACCESS FULL | SALES_PT | 28| 1 | 28| 918K|00:00:00.33 | 4884 | |
---------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("S"."PROD_ID"="T"."PROD_ID" AND "S"."CUST_ID"="T"."CUST_ID" AND
INTERNAL_FUNCTION("S"."TIME_ID")+1=INTERNAL_FUNCTION("T"."TIME_ID")+1 AND "S"."PROMO_ID"="T"."PROMO_ID")
4 - filter("T"."ORDER_DT"=TO_DATE(' 2001-01-01 00:00:00', 'syyyy-mm-dd hh24:mi:ss'))
FULL PWJ를 가능하게 하는 파라미터는 _full_pwise_join_enabled 이며 Default로 True이다. Partial PWJ를 가능하게 하는 기능은 Bloom Pruning이며 파라미터는 _bloom_pruning_enabled이다. 이 파라미터의 Default값은 True이다.
결론
PARTITION WISE JOIN을 설명하는데 PARALLEL + PQ_DISTIRBUTE 힌트 조합은 필요 없다. PARALLEL Operation을 사용할 때 옵티마이저가 잘못된 분배방식을 사용하여 PARTITION WISE JOIN이 실행되지 못할 수 있다. 이때 사용할 수 있는 힌트가 PQ_DISTIRBUTE이며, 이것은 활용법일 뿐이다.
PARTITION PAIR라는 용어 때문에 미리 짝지어 놓았다고 상상함으로써, 마치 조인되는 양측 Partition이 항상 Pair하게 I/O를 한다고 잘못 생각하게 만든다. PWJ의 성능상 장점은 선행집합의 FILTER에 의해서 후행집합에 Access할 파티션의 개수가 줄어든다는 것이다. 따라서 I/O가 PAIR하게 발생되지 않는다. 'PARTITION PAIR로 동작한다'라는 개념은 선행집합에 조건이 하나도 없는 경우이거나 혹은 Partition Key로만 조건이 들어오는 경우뿐이다. 다시 말해 선행집합에 Partition Key조건 이외의 조건이 있다면 PARTITION PAIR를 보장하지 않는다.
PWJ가 실행될 때 성능개선사항 세 가지
첫 번째, 조인 선행집합에 Partition Key 조건이 있으면 Partition Access 범위도 줄어듦으로 BLOCK I/O량도 줄어든다.
두 번째, 선행집합의 모든 FILTER(Partition Key 조건을 포함한)에 의해서 후행집합의 Partition Access 범위가 줄어듦으로 BLOCK I/O량이 줄어든다.
세 번째, JOIN시 큰 테이블을 상대적으로 작은 파티션으로 쪼개어 각각 조인함으로써 PGA 사용량이 감소된다.
첫 번째 개선사항을 정확히 말하면 PWJ의 기능이 아니라 일반적인 Partition Pruning에 의한 성능향상이다. Partition Wise Join의 성능개선은 조인에 의해서 성능이 향상되어야 함으로 두 번째, 세 번째가 진정한 PWJ의 성능개선사항이다.
이제 필자의 차례는 끝나고, 여러분의 차례이다. 주위 사람들에게 PWJ의 정의를 다시 알려주기 바란다.
'Oracle > Data Join Method' 카테고리의 다른 글
| Sort Merge Join에 대한 오만과 편견 (476) | 2011.04.28 |
|---|---|
| 같은 테이블을 두 번 읽었지만 일량이 틀려요 (16) | 2011.01.14 |
| Oracle 조인 방법 25가지 (15) | 2010.02.26 |
| Nested Loop Join 성능향상과 관련된 2가지 원리 (17) | 2009.05.09 |
| Hash Join Right (Semi/Anti/Outer) 의 용도 (17) | 2009.03.02 |