3 부작의 마지막 편
첫 번째, Oracle Data Access Pattern을 정복하라
두 번째, Data Access Pattern중의 파티션에 관련된 Partition Access Pattern 에 이어서 마지막 편이다.
지난 글에서 Data Access Pattern 과 Join Method 이 두 가지는 기본 중에 기본이라고 하였다.
또한 이 두 가지를 정복한다면 SQL 튜닝중의 많은 부분을 커버할 수 있다고 하였다.
튜닝에서 이것보다 중요한 것이 있을까? 이것들 중에 하나라도 빠트린다면 제대로 된 튜닝을 할 수 없다.
단순 분류 5가지
데이터의 연결방법은 단순히 분류해 보면 다음과 같다.
1.Nested Loop Join
2.Sort Merge Join
3.Hash Join
4.Outer Join
5.Using Subquery
세분화
하지만 이것으로는 부족하다. Join Method를 좀더 자세히 나타내면 다음과 같다.
01. Nested Loop Join
02. Sort Merge Join
03. Hash Join
04. Cartesian Join (혹은 Cross Join)
05. Sub Query-In,
06. Sub Query-Any
07. Sub Query-All
08. Sub Query-Exists
09. Subquery Factoring
10. Semi Join-Nested Loop
11. Semi Join-Sort Merge
12. Semi Join-Hash
13. Semi Join-Hash Join Right
14. Anti Join-Nested Loop
15. Anti Join-Sort Merge
16. Anti Join-Hash
17. Anti Join-Hash Join Right
18. Index Join
19. Outer Join-Full
20. Outer Join-Nested Loop
21. Outer Join-Sort Merge
22. Outer Join-Hash
23. Outer Join-Hash Join Right
24. Partition Outer Join
25. Star Query Transformation
극한의 세분화
물론 여기서 더 세분화 시킬 수 있다. 예를 들면 Nested Loop Join은 아래와 같이 분류할 수 있다.
Full(선행집합)-Unique (후행집합)
Full(선행집합)-Range (후행집합)
Range(선행집합)-Range (후행집합)
Unique(선행집합)-Unique (후행집합)
....중간생략
이런 방법으로 Sort Merge Join과 Hash Join까지 계속 나열한다면 아마 끝이 없을 것이다.
단 한 줄도 놓치지 마라
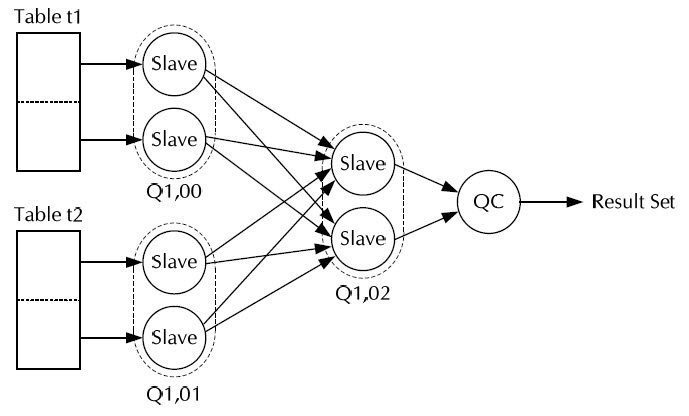
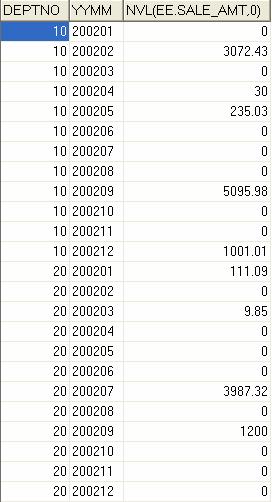
아래의 첨부파일에는 Nested Loop Join도 위와 같은 방법으로 가능한 세분화 하였다. 따라서 이 파일에 담긴 Join method는 25가지가 넘는다. 오늘 이야기하는 조인방법들은 튜닝을 하려면 반드시 정복해야 할 주제이니 꼼꼼히 보기 바란다.
 invalid-file
invalid-file
Oracle Data Join Method
PS
Star Join은 Star Query Transformation이 나온 후로 설 땅을 잃었으므로 나타내지 않았다.
'Oracle > Data Join Method' 카테고리의 다른 글
| Sort Merge Join에 대한 오만과 편견 (476) | 2011.04.28 |
|---|---|
| 같은 테이블을 두 번 읽었지만 일량이 틀려요 (16) | 2011.01.14 |
| Nested Loop Join 성능향상과 관련된 2가지 원리 (17) | 2009.05.09 |
| Hash Join Right (Semi/Anti/Outer) 의 용도 (17) | 2009.03.02 |
| Full Outer Join 의 비밀 (5) | 2009.02.23 |