1.Parallel Query 의 조인시 Row Distribution --> Join 시 Row 의 분배방법 튜닝
2.Parallel Query 의 조인시 또다른 튜닝방법(Parallel Join Filter) --> Join Filter 튜닝
Parallel Query 의 튜닝방법은 많지 않아...
Parallel Query 의 튜닝 방법은 많지 않은데 그 이유는 Parallel Query 기능 자체를 튜닝 하는것이 아니라 Hash 조인의 튜닝 혹은 Block I/O 의 튜닝등 Parallel 자체와는 상관없는 것 을 튜닝하는 경우가 많기 때문이다.
오늘은 3번째로 Parallel Query 자체를 튜닝 하는 또다른 방법에 대하여 논의 할것이다.
잘못된 미신을 믿지 마라.
사실 필자가 Group By Push Down 기능을 설명하는 이유는 잘못된 미신 때문이다.
"Parallel Query 를 수행하면 Group By 가 두번 수행된다. 따라서 Group By 가 있는 SQL 은 Parallel 을 사용하지 마라."
실제 DBA 들의 입에서 오고 가는 말들이다. 잘못된 미신이 퍼져 있다니 참으로 안타까운 현실이 아닐수 없다.
Parallel Query 를 수행하면 Group By 가 무조건 두번 수행되는 것은 아니며 두번 수행 된다면 오히려 성능향상을 기대할 수 있다.
이 글을 읽고 개념을 확실히 하기 바란다.
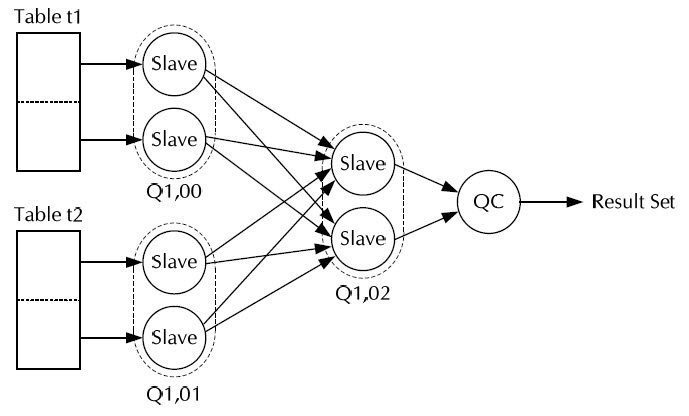
TQ 를 알고 가자.
먼저 Group By Push Down 기능을 설명하기 전에 TQ(Table queues) 개념을 알아야 한다.
1.TQ 는 Processes간의 데이터를 주고받는 기능을 한다.
2.하나의 TQ 는 여러개의 parallel Slave 를 가진다.
3.TQ 는 Parallel Query 수행시 생성된다.
상세한 개념은 위에서 언급한 글중 2번을 참조하기 바란다.
Group By Push Down 이 뭐야?
1.Group By Push Down 이란 TQ 에 데이터를 전달하기 전에 Group By 를 수행하여 데이터의 건수를 대폭 줄인후에 TQ 에 데이터를 전달함으로서 일량을 줄이고 성능을 향상시키는데 목적이 있다.
2.Group By Push Down 은 Parallel Query 에 Group By 가 포함되어 있는 경우 발생한다.
원리는 같다.
이기능은 마치 DW 용 SQL 작성시 Fact 테이블(대용량) 을 먼저 Group By 한후에 Dimension 테이블(소용량 코드 테이블)과 조인하여 조인 건수를 대폭 줄임으로서 성능 향상을 꾀하는것과 같은 개념이다. 이기능은 오라클이 자동으로 해주기도 하는데 이것을 "Group By Placement" 라고 하며 추후 따로 글을 올릴 생각이다.
어떻게 하는건데?
Group By Push Down을 수행하기위해 아래의 SQL 을 보자.
환경: Oracle 11g 11.1.0.7
prod_id, cust_id, COUNT (*) cnt
FROM sh.sales A
GROUP BY prod_id, cust_id;
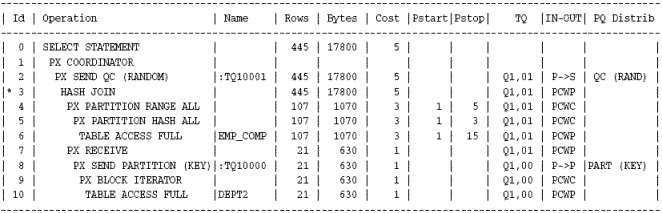
GBY_PUSHDOWN 란 힌트를 사용하였으며 아래의 Plan 에서 보는바와 같이 성공적으로 Group By Push Down 이 수행되었다.
---------------------------------------------------------------------------
| Id | Operation | Name | E-Rows | Used-Mem | Used-Tmp|
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | |
| 1 | PX COORDINATOR | | | | |
| 2 | PX SEND QC (RANDOM) | :TQ10001 | 359K| | |
| 3 | HASH GROUP BY | | 359K| 2197K (0)| |
| 4 | PX RECEIVE | | 359K| | |
| 5 | PX SEND HASH | :TQ10000 | 359K| | |
| 6 | HASH GROUP BY | | 359K| 3284K (1)| 1024 |
| 7 | PX BLOCK ITERATOR | | 918K| | |
|* 8 | TABLE ACCESS FULL| SALES | 918K| | |
---------------------------------------------------------------------------
원래 수행되어야 하는 Group By 는 Id 기눈으로 3번(파랑색 부분) 이지만 Id 6번에서 먼저 Group By 가 수행되었다. 그이유는 Id 5번의 :TQ10000 에게 데이터를 전달하기전에 데이터를 줄여서 성능을 향상시키기 위함이다. 실제로 옵티마이져는 Id 5번에서 Group By 된 359K Row에 대한 데이터만 처리 할것으로 예상하고 있다.
튜닝은 Trade Off 이다.
주의 사항이 있다. 실제로 TQ의 일량은 줄어들지만 불필요한 Hash Group By 혹은 Sort Group By 가 수행되어 성능이 더 나빠질수 도 있다는것이다. Id 6 에서 Hash Area Size 가 부족하여 Disk 작업(Used-Tmp 부분 참조)이 발생하였다. 따라서 Group By 를 하면 건수가 몇배~ 몇십배이상 줄어드는 경우에 적용하여야 하며 Disk 에서 Sort 및 Hash 작업이 발생하는 경우는 PGA 튜닝을 동반하여야 한다.
Group By Push Down 이 적용되지 않은 Plan 을 보여다오.
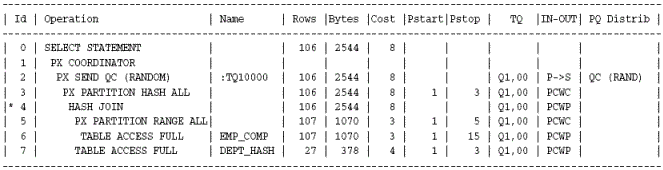
GBY_PUSHDOWN 힌트 대신에 NO_GBY_PUSHDOWN 힌트를 사용하면 Group By Push Down이 발생하지 않는다.
prod_id, cust_id, COUNT (*) cnt
FROM sh.sales A
GROUP BY prod_id, cust_id;
----------------------------------------------------------------
| Id | Operation | Name | E-Rows | Used-Mem |
----------------------------------------------------------------
| 0 | SELECT STATEMENT | | | |
| 1 | PX COORDINATOR | | | |
| 2 | PX SEND QC (RANDOM) | :TQ10001 | 359K| |
| 3 | HASH GROUP BY | | 359K| 4492K (0)|
| 4 | PX RECEIVE | | 918K| |
| 5 | PX SEND HASH | :TQ10000 | 918K| |
| 6 | PX BLOCK ITERATOR | | 918K| |
|* 7 | TABLE ACCESS FULL| SALES | 918K| |
----------------------------------------------------------------
정상적으로 Group By 가 한번만 수행되었지만 옵티마이져는 TQ 의 일량이 Group By Push Down 이 적용된 SQL 에 비하여 918K 로 약 3배정도 중가한것으로 판단하였고 실제로도 그렇게 수행된다.
Group By Push Down은 11g 신기능이 아니다.
GBY_PUSHDOWN / NO_GBY_PUSHDOWN 등의 힌트는 11g 에서 새로 나온 것 이다. 하지만 이전버젼에서도 _groupby_nopushdown_cut_ratio 파라미터를 0 으로 세팅하면 Group By Push Down 을 강제로 수행할수 있다. 이파라미터의 Default 값은 3 이며 이경우는 Group By Push Down 의 수행여부를 옵티마이져가 판단한다. 아래는 옵티마이져의 Costing 과정을 10053 Trace 에서 발췌한 것이다.
Number of join permutations tried: 1
*********************************
GROUP BY adjustment factor: 0.707107
GROUP BY cardinality: 359386.000000, TABLE cardinality: 918843.000000
Costing group-by pushdown:
SORT ressource Sort statistics
Sort width: 598 Area size: 552960 Max Area size: 104857600
Degree: 1
Blocks to Sort: 563 Row size: 20 Total Rows: 229711
Initial runs: 2 Merge passes: 1 IO Cost / pass: 306
Total IO sort cost: 869 Total CPU sort cost: 230852464
Total Temp space used: 4629000
Distribution cost: resc_cpu: 91885309 resp_cpu: 22971327
Costing final group-by:
Subtracting no-pushdown group-by:
SORT ressource Sort statistics
... 이후 생략
적재적소에 사용하자.
실제로 옵티마이져는 Group By Push Down 의 수행여부를 Cost 로서 판단하고 있으므로 기본적으로는 오라클에 맏기면 된다. 하지만 아주 복잡한 SQL 이나 옵티마이져가 판단을 잘못할 경우에 Group By Push Down 을 수동으로 적절히 발생시킨다면 성능향상을 꾀할수 있다.
편집후기:
필자가 이글을 올린다고 하니 어느 지인은 컨설턴트의 밥그릇 타령을 한다.
다시말해 이런것들을 모든 개발자가 안다면 컨설턴트가 설자리가 없다는 것인데...
글쎄...
여러분은 어떻게 생각하는가?
'Oracle > Optimizer' 카테고리의 다른 글
| Semi Join 의 재조명 (5) | 2009.08.31 |
|---|---|
| Group By 를 먼저 수행하고 Join 하라( Group By Placement ) (4) | 2009.08.24 |
| 11g DBMS_STATS 패키지 성능개선의 3가지 원리 (3) | 2009.06.15 |
| PM ( Predicate Move Around ) : Where 조건을 다른뷰에 이동시켜라. (2) | 2009.06.09 |
| Query Transformation Internal ( about JPPD using Lateral View ) (0) | 2009.04.20 |