PRO * C 나 PL/SQL 에서 많은양의 데이터를 Cursor For Loop로 선언한후를 건건이 Update/Delete 등을 처리하는 경우가 많이 있다.
집합처리가 유리하겠지만 그것이 불가능한 경우나 집합처리가 가능하지만 SQL 이 너무 길어지는 경우는
유지보수의 관점에서 Cursor For Loop 를 사용해야 한다.
하지만 많은 개발자들이 일반적으로 Cursor For Loop 내에서 아직도 PK 인덱스나 Unique 인덱스를 사용하여
DML 문을 실행하고 있다.
오늘은 Cursor for Loop 처리시 개발자들이 일반적으로 코딩하는 방식의 비효율성을 설명하고 Solution 을 제시한다.
아래는 테스트용 테이블및 인덱스 생성 스크립트 이다.
with generator as ( select /*+ materialize */ rownum as id
from all_objects
where rownum <= 3000 )
select /*+ ordered use_nl(v2) */
10000 + rownum id,
trunc(dbms_random.value(0,5000)) n1,
rownum score,
rpad('x',1000) probe_padding
from generator v1,
generator v2
where rownum <= 100000; --> t1 테이블 생성(10만건)
alter table T1 add constraint T1_PK primary key(id); --> id 에 PK 인덱스를 생성함.
EXEC dbms_stats.gather_table_stats(user, 'T1', cascade => true);
1.아래는 Curso For Loop 를 사용하여 건건이 Update 하는 가장 흔하게 볼수있는 PL/SQL 패턴이다.
cursor c is select * from t1 for update ;
begin
for rec in c loop
update /*+ pk_index_test */ t1 --> 10 만번 PK 인덱스를 사용하여 UPDATE
set score = score + 0
where id = rec.id;
end loop;
commit;
end;
/
위 PL/SQL 의 ELAPSED TIME 은 11.80 초 이며 이수치는 10번을 실행하여 평균값을 취한것이다.
2.SOLUTION
cursor c is select * from t1 for update ;
begin
for rec in c loop
update /*+ current_of_test */ t1 --> 10만번 current of 를 사용하여 UPDATE
set score = score + 0
where current of c ;
end loop;
commit;
end;
/
위 PL/SQL 의 ELAPSED TIME 은 10.70 초 이며 이수치는 10번을 실행하여 평균값을 취한것이다.
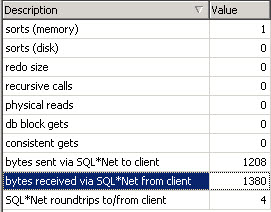
물론 테스트를 정확히 하기위하여 각각의 테스트시에 buffer cache 를 flush 하였다.
PK 인덱스를 이용한 UPDATE 보다 Current of 를 사용한 Update 가 10% 정도 빠른걸 알수 있다.
그렇다면 10%의 차이는 어디서 오는가?
비밀은 v$sqlarea 에서 수행된 SQL 을 보면 알수 있다.
from v$sqlarea
where sql_text like '%current_of_test%';
결과 :
---------------------------------------------------------------------------
UPDATE /*+ current_of_test */ T1 SET SCORE = SCORE + 0 WHERE ROWID = :B1
위의 결과에서 처럼 WHERE CURRENT OF 를 사용하면 ROWID 를 이용하여 Accsess 하는것을 알수 있다.
Rowid Access 는 오라클에서 가장 빠른 Access 방식이다.
주의할 점은 WHERE CURRENT OF 를 사용하려면 Main Cursor 가 반드시 SELECT FOR UPDATE 문이어야
한다는 것이다.
하지만 FOR UPDATE 가 없는 커서에서도 아래처럼 사용하면 같은 효과를 누릴수 있다.
cursor c is select t1.rowid, t1.* from t1 ;
begin
for rec in c loop
update /*+ rowid_test */ t1
set score = score + 0
where rowid = rec.rowid;
end loop;
commit;
end;
결론:
다시한번 기본(SQL 및 PL/SQL)이 얼마나 중요한지 알수 있는 테스트 이다.
Where Current of 를 모르는 사람은 많이 없을것이다.
하지만 Where Current of 절을 사용하면 Index Access에 의한 부하를 없앨수 있다는 사실을 아는사람은
의외로 많지 않다.
여러분의 프로그램이 이런환경에서 PK 인덱스를 사용하도록 코딩이 되어 있다면 지금 당장 달려가서
프로그램을 수정하라고 말하고 싶다.
'Oracle > PL/SQL Tuning' 카테고리의 다른 글
| SQL*Net message from client 이벤트는 항상 Idle Event 인가? (Pipelined Table Function 의 용도) (8) | 2008.08.23 |
|---|