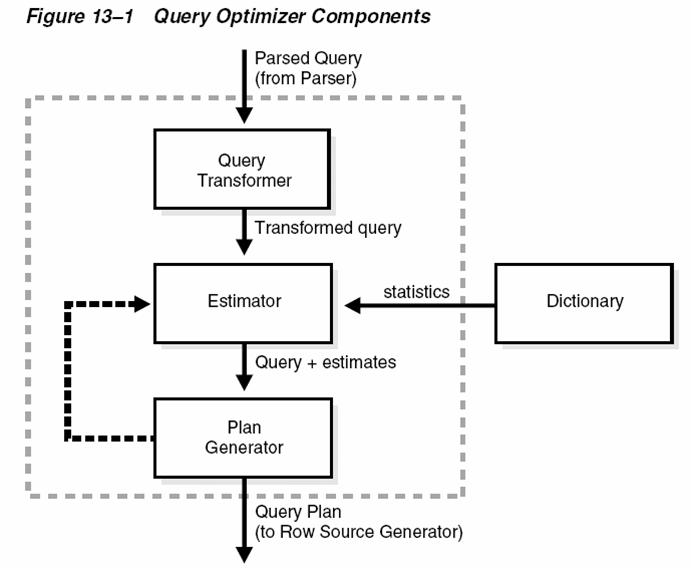
집계함수 내부에 Distinct를 사용할 수 있다는 것은 많은 사람들이 알고 있다. 하지만 실제로 그렇게 사용했을 때 내부적으로 무슨 일이 일어나는지 아는 사람은 드물다. 한걸음 더 나아가서 COUUNT(COL) 대신에 COUNT(Distinct COL)를 사용했다면 분명히 추가적인 부하가 존재할 것인데, 그 부하를 어떻게 해결할 것인가를 아는 사람은 거의 없을 것이다. 만약 그렇다면 SQL을 실행할 때 마다 성능이 느려질 것이고 문제를 해결할 수 없을 것이다. 여러분들에게는 그런 일이 발생하지 않는다. 이미 이 글을 읽고 있기 때문이다.
이 글은 위에서 언급된 두 가지 문제를 다룬다. 즉 내부적으로 어떤 변화가 발생하는지 알아보고, 추가적인 부하를 어떻게 없앨 수 있는지도 연구해보자.
SQL 변경에 따른 내부적인 변화를 알아보는 가장 좋은 방법은 비교하는 것이다. 다시 말해, COUUNT(COL)로 실행했을 때의 일량과 COUNT(Distinct COL)로 사용했을 때의 일량을 비교해 보는 것이다. 따라서 우리는 SQL 두 개를 실행한 다음 각각의 작업량(실행통계)을 비교할 것이다.
환경: 오라클 11.2.0.1
CREATE TABLE SALE_T AS SELECT * FROM SALES;
SELECT /*+ NO_USE_HASH_AGGREGATION */
S.PROD_ID
,COUNT(S.CHANNEL_ID)
,SUM(S.AMOUNT_SOLD)
,SUM(S.QUANTITY_SOLD)
FROM SALE_T S
GROUP BY S.PROD_ID;
-----------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | A-Rows | A-Time | Buffers | Used-Mem |
-----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 72 |00:00:01.12 | 4440 | |
| 1 | SORT GROUP BY | | 1 | 72 |00:00:01.12 | 4440 | 6144 (0)|
| 2 | TABLE ACCESS FULL| SALE_T | 1 | 918K|00:00:00.32 | 4440 | |
-----------------------------------------------------------------------------------------
위의 SQL이 실행되는데 시간이 1.12초 걸렸고 PGA는 6144 Byte를 소모하였다. 그런데 아래처럼 COUNT에 DISTINCT를 추가를 추가한다면 어떻게 될까?
SELECT /*+ NO_QUERY_TRANSFORMATION */
S.PROD_ID
,COUNT(DISTINCT S.CHANNEL_ID)
,SUM(S.AMOUNT_SOLD)
,SUM(S.QUANTITY_SOLD)
FROM SALE_T S
GROUP BY S.PROD_ID;
-----------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | A-Rows | A-Time | Buffers | Used-Mem |
-----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 72 |00:00:02.20 | 4440 | |
| 1 | SORT GROUP BY | | 1 | 72 |00:00:02.20 | 4440 |14336 (0)|
| 2 | TABLE ACCESS FULL| SALE_T | 1 | 918K|00:00:00.33 | 4440 | |
-----------------------------------------------------------------------------------------
작업량이 증가된 이유
Distinct 만 추가했을 뿐인데 시간이 약 두 배나 걸리고 PGA도 약 두 배로 사용하였다. 그 이유는 Operation에는 나오지 않지만 내부적으로 SORT UNIQUE가 실행되기 때문이다. 즉 PROD_ID별로 SORT GROUP BY를 했음에도 CHANNEL_ID 별로 SORT UNIQUE를 다시 실행해야 한다. 약 92만 건의 데이터를 CHANNEL_ID 별로 SORT한 후에 중복을 제거하는 작업이 Distinct에 의해서 추가된 것이다. 그렇기 때문에 FULL TABLE SCAN의 수행시간은 거의 같지만 SORT GROUP BY의 수행시간이 0.8초에서 1.87초로 늘어나고 PGA사용량도 두 배가 된 것이다.
비효율을 제거하는 방법
첫 번째 의문점인 집계함수에 Distinct가 추가되면 어떤 일이 발생하는지 알아냈다. 그렇다면 두 번째 문제인 비효율(추가적인 Sort와 중복제거)을 없애는 방법은 무엇일까? SQL을 아래처럼 튜닝 할 수 있을 것이다.
SELECT /*+ NO_USE_HASH_AGGREGATION */
PROD_ID,
COUNT(S.CHANNEL_ID),
SUM(S.AMOUNT_SOLD),
SUM(S.QUANTITY_SOLD)
FROM (SELECT /*+ NO_USE_HASH_AGGREGATION */
S.CHANNEL_ID ,
S.PROD_ID ,
SUM(S.AMOUNT_SOLD) AMOUNT_SOLD,
SUM(S.QUANTITY_SOLD) QUANTITY_SOLD
FROM SALE_T S
GROUP BY PROD_ID, CHANNEL_ID) S
GROUP BY S.PROD_ID ;
-------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | A-Rows | A-Time | Buffers | Used-Mem |
-------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 72 |00:00:01.39 | 4440 | |
| 1 | SORT GROUP BY NOSORT| | 1 | 72 |00:00:01.39 | 4440 | |
| 2 | VIEW | | 1 | 228 |00:00:01.39 | 4440 | |
| 3 | SORT GROUP BY | | 1 | 228 |00:00:01.39 | 4440 |18432 (0)|
| 4 | TABLE ACCESS FULL| SALE_T | 1 | 918K|00:00:00.33 | 4440 | |
-------------------------------------------------------------------------------------------
비록 PGA 사용량은 약간 늘어났지만 수행시간은 DISTINCT가 없는 SQL과 비슷해졌다. 먼저 PROD_ID, CHANNEL_ID로 GROUP BY 되었기 때문에 인라인뷰 외부에서는 Distinct를 할 필요가 없다. 다른 말로 표현하면 먼저 GROUP BY했기 때문에 PROD_ID 별로는 CHANNEL_ID가 UNIQUE 하다. 따라서 인라인뷰 외부에서는 Distinct가 필요 없게 된 것이다.
더 좋은 것은 실행계획의 Id 1을 보면 SORT GROUP BY NOSORT가 나온다. NOSORT가 나온 이유는 인라인뷰가 이미 PROD_ID로 SORT 되어있기 때문에 더 이상의 SORT는 필요 없기 때문이다. 따라서 추가적인 Group By의 부하는 거의 없다. 이렇게 튜닝하면 Distinct에 의한 SORT UNIQUE의 부하가 대부분 사라진다.
옵티마이저가 사람을 대신한다
집계함수에 Distinct를 사용한다면 무조건 위의 SQL처럼 튜닝 해야 하는가? 그건 아니다. 오라클 11.2를 사용한다면 Logical Optimizer가 SQL을 자동으로 변경시켜 준다. 아래의 튜닝 되지 않은 SQL을 실행시켜보자.
SELECT /*+ NO_USE_HASH_AGGREGATION(@"SEL$5771D262") */
S.PROD_ID
,COUNT(DISTINCT S.CHANNEL_ID)
,SUM(S.AMOUNT_SOLD)
,SUM(S.QUANTITY_SOLD)
FROM SALE_T S
GROUP BY S.PROD_ID
---------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | A-Rows | A-Time | Buffers | Used-Mem |
---------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 72 |00:00:01.39 | 4440 | |
| 1 | SORT GROUP BY NOSORT| | 1 | 72 |00:00:01.39 | 4440 | |
| 2 | VIEW | VW_DAG_0 | 1 | 228 |00:00:01.39 | 4440 | |
| 3 | SORT GROUP BY | | 1 | 228 |00:00:01.39 | 4440 |18432 (0)|
| 4 | TABLE ACCESS FULL| SALE_T | 1 | 918K|00:00:00.32 | 4440 | |
---------------------------------------------------------------------------------------------
Outline Data
-------------
/*+
BEGIN_OUTLINE_DATA
…생략
TRANSFORM_DISTINCT_AGG(@"SEL$1")
…생략
END_OUTLINE_DATA
*/
오라클이 내부적으로 TRANSFORM_DISTINCT_AGG 힌트를 사용하였고 SQL을 자동으로 변경하였다. 실행계획도 튜닝된 SQL과 같다. 즉 11.2 버전부터는 집계함수내부에 Distinct가 존재하면 Logical Optimizer가 SQL을 변경시킴으로써 성능이 향상되는 것이다. 이 기능을 Distinct To Aggregation이라고 부른다.
아래는 10053 Trace 파일의 내용이다. 내용이 많지만 개념은 간단하다. 쿼리변환 전의 SQL을 보여주고 쿼리변환 후의 SQL을 보여준다. 그리고 두 개의 SQL 사이에는 쿼리블럭 SEL$1이 Distinct To Aggregation 기능에 의해서 두 개로 찢어지는 과정(SPLIT QUERY BLOCK)을 보여준다.
DAGG_TRANSFORM: transforming query block SEL$1 (#0)
qbcp (before transform):******* UNPARSED QUERY IS *******
SELECT "S"."PROD_ID" "PROD_ID",COUNT(DISTINCT "S"."CHANNEL_ID") "COUNT(DISTINCTS.CHANNEL_ID)",SUM("S"."AMOUNT_SOLD") "SUM(S.AMOUNT_SOLD)",SUM("S"."QUANTITY_SOLD") "SUM(S.QUANTITY_SOLD)" FROM "TLO"."SALE_T" "S" GROUP BY "S"."PROD_ID"
pgactx->ctxqbc (before transform):******* UNPARSED QUERY IS *******
SELECT "S"."PROD_ID" "PROD_ID",COUNT(DISTINCT "S"."CHANNEL_ID") "COUNT(DISTINCTS.CHANNEL_ID)",SUM("S"."AMOUNT_SOLD") "SUM(S.AMOUNT_SOLD)",SUM("S"."QUANTITY_SOLD") "SUM(S.QUANTITY_SOLD)" FROM "TLO"."SALE_T" "S" GROUP BY "S"."PROD_ID"
Registered qb: SEL$5771D262 0xea51918 (SPLIT QUERY BLOCK FOR DISTINCT AGG OPTIM SEL$1; SEL$1)
---------------------
QUERY BLOCK SIGNATURE
---------------------
signature (): qb_name=SEL$5771D262 nbfros=1 flg=0
fro(0): flg=0 objn=76169 hint_alias="S"@"SEL$1"
Registered qb: SEL$C33C846D 0xde78e84 (MAP QUERY BLOCK SEL$5771D262)
---------------------
QUERY BLOCK SIGNATURE
---------------------
signature (): qb_name=SEL$C33C846D nbfros=1 flg=0
fro(0): flg=5 objn=0 hint_alias="VW_DAG_0"@"SEL$C33C846D"
qbcp (after transform):******* UNPARSED QUERY IS *******
SELECT "VW_DAG_0"."ITEM_2" "PROD_ID",COUNT("VW_DAG_0"."ITEM_1") "COUNT(DISTINCTS.CHANNEL_ID)",SUM("VW_DAG_0"."ITEM_4") "SUM(S.AMOUNT_SOLD)",SUM("VW_DAG_0"."ITEM_3") "SUM(S.QUANTITY_SOLD)" FROM (SELECT /*+ NO_USE_HASH_AGGREGATION */ "S"."CHANNEL_ID" "ITEM_1","S"."PROD_ID" "ITEM_2",SUM("S"."QUANTITY_SOLD") "ITEM_3",SUM("S"."AMOUNT_SOLD") "ITEM_4" FROM "TLO"."SALE_T" "S" GROUP BY "S"."CHANNEL_ID","S"."PROD_ID") "VW_DAG_0" GROUP BY "VW_DAG_0"."ITEM_2"
Distinct To Aggregation 쿼리변환은Heuristic Query Transformation에 속한다. _optimizer_distinct_agg_transform 파라미터로 이 기능을 제어할 수 있고 Default로 true이다. 힌트로는 TRANSFORM_DISTINCT_AGG / NO_TRANSFORM_DISTINCT_AGG 를 사용할 수 있다.
이제 우리는 집계함수에 Distinct가 추가되면 SORT UNIQUE의 부하로 성능이 느려짐을 안다. 또 Distinct 대신에 Group By를 사용하여 그 부하를 대부분 없애는 방법도 알게 되었다. 하지만 이제는 이런 일들을 옵티마이저가 대신하게 되었다. 이런 기능들이 계속 추가된다면 언젠가는 튜너라는 직업이 사라지 않을까? 만약 튜너가 없어진다면, 그 후에 옵티마이저를 연구하는 사람까지 사라질 것이다. 왜냐하면 옵티마이저를 연구하는 사람은 튜너를 위해 존재하기 때문이다.
PS
다들 잘 지내시죠? 개인 사정으로 지난 2년간 뵙지 못했습니다. 5월달에 글을 한 두개 더 올릴 생각 입니다. 기대해 주세요. 5월 중순 부터는 바빠서 글쓰기가 힘들 것 같습니다.
그럼 건강하세요.
'Oracle > Optimizer' 카테고리의 다른 글
| Cardinality Feedback이 위험할 때 (10) | 2010.10.25 |
|---|---|
| 공지 - Cardinality Feed Back이 위험할 때 (1) | 2010.10.22 |
| union과 union all의 숨겨진 차이점 (6) | 2010.10.18 |
| 메트릭스나 터미네이터는 먼 미래의 이야기 인가? (2) | 2010.04.28 |
| 해결사 되기 (15) | 2010.02.04 |



 invalid-file
invalid-file







 invalid-file
invalid-file