오늘은 지난시간에 논의 했던 SubQuery Flattening 에 이어서 쿼리변형이 발생하지 않는 Access 서브쿼리 와 Filter 서브쿼리, Early Filter 서브쿼리 에 대해서 이야기 할것이다.
튜닝관점의 서브쿼리의 분류
1.Unnesting 서브쿼리 : 참조
2.Semi Join/Anti Join : 참조
3.Access 서브쿼리 : 쿼리변형이 없음
1)흔히말하는 제공자 서브쿼리임.(서브쿼리부터 풀려서 메인쿼리에 값이 제공된다.)
2)위의 1번 2번과 다르게 Plan 에 메인쿼리와 서브쿼리의 Join 이 없다.
3)힌트: 특별한 힌트없음.
다만 /*+ no_unnest */ 를 사용하여 SubQuery Flattening 을 방지하고
서브쿼리로부터 제공되는 메인쿼리의 컬럼에 인덱스가 생성되어 있으면됨.
4) 주의사항: corelate 서브쿼리는 제공자 서브쿼리가 될수 없음.
4.Filter 서브쿼리 : 쿼리변형이 없음
1)흔히 말하는 확인자 서브쿼리임.(메인쿼리의 값을 제공받아 서브쿼리에서 체크하는 방식임)
2)위의 1번 2번과 다르게 Plan 에 메인쿼리와 서브쿼리의 Join 이 없고 Filter 로 나온다.
3)Filter SubQuery 의 특징은 메인쿼리의 From 절에 있는 모든 테이블을 엑세스후에 가장마지막에
서브쿼리가 실행된다는 것이다.
4) 힌트: 특별한 힌트없음.
다만 /*+ no_unnest */ 를 사용하여 SubQuery Flattening 을 방지하고
메인쿼리로부터 제공되는 서브쿼리의 조인컬럼에 인덱스가 생성되어 있으면됨.
5.Early Filter 서브쿼리 : 쿼리변형이 없음
1)Filter SubQuery 와 같은 방식이지만 서브쿼리를 최대한 먼저 실행하여 데이터를 걸러낸다.
2)힌트 : 메인쿼리에 push_subq 힌트사용 (10g 이후부터는 서브쿼리에 힌트사용해야함)
3)주의사항: 많은 튜닝책에서 "Push_subq 힌트를 사용하면 제공자 서브쿼리를 유도한다" 라고
되어 있으나 이는 잘못된 것이다.
push_subq 힌트를 사용하면 확인자 서브쿼리(Filter 서브쿼리)를 유도하지만 최대한
먼저 수행된다.
아래의 스크립트를 보자
|
3.Access 서브쿼리 select small_vc from min_max mm1 where mm1.id_parent = 100 and mm1.id_child = ( select max(mm2.id_child) from min_max mm2 where mm2.id_parent = 100 ) ; |
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 108 | 4 |
| 1 | TABLE ACCESS BY INDEX ROWID | MIN_MAX | 1 | 108 | 2 |
|* 2 | INDEX UNIQUE SCAN | MM_PK | 1 | | 1 |
| 3 | SORT AGGREGATE | | 1 | 8 | |
| 4 | FIRST ROW | | 10 | 80 | 2 |
|* 5 | INDEX RANGE SCAN (MIN/MAX)| MM_PK | 10 | 80 | 2 |
--------------------------------------------------------------------------
위의 plan 을 보면 실행순서가 헷갈릴수 있다.
결론을 이야기 하자면 id 기준으로 실행 순서는 5 -> 4 -> 3 -> 2 -> 1 이다.
즉 맨밑에서부터 위로 실행된다. (서브쿼리부터 실행해서 메인쿼리에 1건을 제공하였다)
특정일자에 max 일련번호를 찾아서 처리해야할때 많이 사용하는 SQL 패턴이다.
corelate 서브쿼리가 아니고 서브쿼리로부터 제공되는 메인쿼리의 컬럼에 인덱스가 생성되어 있는 경우만이
Access 서브쿼리로 풀린다.(mm1.id_child 컬럼에 인덱스가 있어야 한다)
다음의 두가지 경우에서만 Access 서브쿼리를 사용해야한다.
1) 서브쿼리의 엑세스건수가 적고 서브쿼리의 결과를 제공받은 메인쿼리도 엑세스 건수가 적어야 한다.
2) 비록 서브쿼리의 엑세스 건수가 많지만 그결과를 제공받은 메인쿼리의 엑세스 건수가 적다면 사용할수 있다.
왜냐하면 Access 서브쿼리는 단한번만 수행되기 때문이다.
이경우 메인쿼리의 테이블이 mm1.id_child 컬럼기준으로 클러스트링 팩터가 좋다면 서브쿼리가 힘을 얻게 된다.
하지만 이경우는 반드시 Semi Join 이나 Unnesting 서브쿼리, Filter 서브쿼리등과 성능을 비교해 보아야 한다.
|
4.Filter 서브쿼리 select small_vc from t1 where n2 between 100 and 200 or exists ( select null from t2 where t2.n1 = t1.n1 and t2.mod1 = 15 ); |
------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost |
------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 597 | 11343 | 28 |
|* 1 | FILTER | | | | |
| 2 | TABLE ACCESS FULL | T1 | 10000 | 185K| 28 |
|* 3 | TABLE ACCESS BY INDEX ROWID | T2 | 1 | 7 | 2 |
|* 4 | INDEX RANGE SCAN | T2_PK | 1 | | 1 |
------------------------------------------------------------------------
메인쿼리의 WHERE 절에 조건이 있고 OR 로 EXISTS 를 사용하게 되면 CBQT(Cost Based Query Transformation) 가 작동을 하지않는다.
따라서 위의 경우처럼 OR 가 있는 서브쿼리는 SubQuery Flattening 이 발생하지 않고 확인자 서브쿼리로 풀리게 된다.
위의 경우와는 반대로 10g 에 와서는 옵티마이져가 왠만하면 Semi Join 이나 서브쿼리 Unnesing등의 쿼리변형을 하게되므로
대부분의 경우 강제로 NO_UNNEST 힌트를 사용해야지만 Filter 서브쿼리로 풀리게 된다.
주의할점은 10g 에서 서브쿼리가 filter 로 풀릴경우 Plan 에서는 Filter Operation 이 사라지는 경우가 많이 있다.
Plan 이 잘못된것이 아니니 참고하기 바란다.
상식이지만 노파심에서 다시한번 이야기 하지만 Filter 서브쿼리는 메인쿼리로부터 조인되는 컬럼(t2.n1)에 반드시 인덱스가
만들어져 있어야 한다.
그렇지 않으면 성능은 기대할수 없다.
Filter 서브쿼리는 다음의 두가지 경우에 사용하여야 한다.
1) 메인쿼리의 where 절에 똑똑한 조건들이 많아서 엑세스 건수가 적을때
이경우는 filter Operation 이 몇번 발생하지 않게 되므로 당연히 유리하다.
2) 메인쿼리는 비록 엑세스건수가 많지만 서브쿼리의 체크조건이 True 인경우가 많은경우
이경우는 특히 부분범위처리시 유리하다.
왜냐하면 비록 건수가 많지만 서브쿼리의 체크조건이 True 인경우가 많으므로 화면에 바로바로 나오게 된다.
하지만 배치 프로그램처럼 전체범위를 목적으로 하는경우는 성능이 저하되므로 주의하여야 한다.
이때도 서브쿼리의 t2.n1 컬럼기준으로 서브쿼리 테이블의 클러스트링 팩터가 좋다면 성능이 향상되는데 물론 메인쿼리가
sort 되는경우 이거나 인덱스의 사용등으로 자동 sort 가 되어 서브쿼리에 데이터가 공급되는 경우에 한해서다.
|
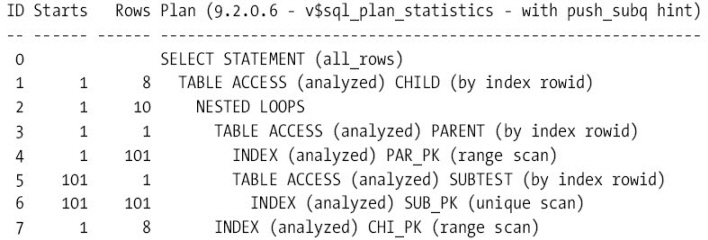
5.Early Filter 서브쿼리
SELECT par.small_vc1, chi.small_vc1 |
|
|
Early Filter 서브쿼리를 설명하려면 최소한 메인쿼리에 2개의 테이블이 있어야 한다.
위의 서브쿼리를 보면 PARENT 쪽 메인쿼리만 풀리면 서브쿼리가 동작할수 있다.
다시말하면 CHILD 쪽의 컬럼이 서브쿼리에 없으므로 PARENT 쪽의 컬럼만 상수화 되면 서브쿼리가 작동할수 있게
되는 것이다.
실행순서는 PLAN 에서 보는것과 같이 PARENT -> subtest -> CHILD 이다 하지만 불행하게도 오라클은 대부분의 Filter 쿼리에서 서브쿼리는 가장마지막에 작동한다.
즉 대부분의 Filter 쿼리에서 PARENT ->CHILD -> subtest 순으로 풀리게 된다.
이때 사용할수 있는 힌트가 push_subq 힌트이다.
최대한 먼저 데이터를 걸러내어 그다음 테이블과 조인시 건수를 줄이고 싶을때 탁월한 효과를 내는 힌트이다.
반드시 여러분의 환경에서 여러분들의 쿼리로 push_subq 힌트가 있을때와 없을때의 차이를 느껴보기 바란다.
결론:
이상으로 서브쿼리의 5가지 분류에 대하여 알아 보았다.
서브쿼리는 실제 프로젝트 환경에서 자주 사용하므로 5개의 분류는 나름대로 특징과 장단점이 있어서 적재적소에 사용할경우
엄청난 이득을 가져올수 있지만 그렇지 않은경우 독이 될수 있음을 기억하자.
Reference :
1)Query Optimization in Oracle Database10g Release 2(White Paper)
2)COST BASED QUERY TRANSFORMATIONS CONCEPT
AND ANALYSIS USING 10053 TRACE(Riyaj Shamsudeen)
3)Cost Based Oracle Fundamentals(Jonathan Lewis) with Blog (http://jonathanlewis.wordpress.com)
편집후기 :
요즘 필자의 프로젝트가 막바지로 치달리고 있어서 엄청 바쁘지만 블로그는 블로그대로 관리를 해야하니 엄청 스트레스가 된다.
블로그만 쓰며 살수는 없는걸까?^^
'Oracle > Optimizer' 카테고리의 다른 글
| Access Sub Query 의 함정 (4) | 2008.11.19 |
|---|---|
| 오라클은 얼마나 똑똑한가? (3) | 2008.10.10 |
| Using Sub query Method (Sub query Flattening ) (10) | 2008.09.09 |
| 히든 파라미터 설정변경의 위험성 (0) | 2008.06.23 |
| NO Costing in CBO (1) | 2008.05.28 |





