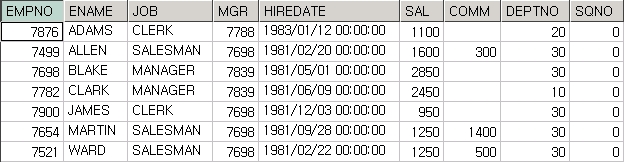
▶분석함수의 비효율을 찾는 방법
▶분석함수의 성능개선 원리
▶분석함수의 실행계획 3부 - 심화과정의 모범답안
이번 글이 분석함수의 실행계획 시리즈의 마지막이다. 1부와 2부에서 분석함수의 실행계획에 대해서 알아보았다. 이 글(3부)은 새로 작성되었으며, 이전 글( 문제 출제용 )은 삭제하지 않고 그대로 두었음을 밝혀둔다. 나중에라도 문제를 풀어볼 사람은 이 글(답안)을 보지 말고, 이전 글을 보기 바란다. 각각의 답안은 오렌지색으로 표시해 두었으므로 쉽게 채점할 수 있을 것이다.
분석함수의 다섯 가지 원리
많은 수의 개발자, DBA, 튜너들은 분석함수를 만나면 식은 땀을 흘린다. 왜냐하면, 분석함수의 비효율을 어떻게 찾을 수 있는지, 또 그 비효율은 어떻게 제거 할 수 있는지 알 수 없기 때문이다. 기껏해야 분석함수의 over절을 만족하는 적절한 인덱스를 생성하는 정도이다. 어쩌면 이런 결과들은 당연하다고 볼 수 있다. 매뉴얼이나 튜닝 책에 분석함수의 비효율을 발견하는 방법과 개선방법에 대한 언급이 별로 없기 때문이다. 이런 어려움을 겪고 있는 여러 사람들의 요구에 의해서 이 글이 만들어졌다. 분석함수의 비효율을 찾고, 성능을 향상시킬 수 있는 다섯 가지 방법을 공개하니, 많은 사람들이 적용하여 더 이상 식은 땀은 흘리지 않기 바란다.
SQL 두 개에 5가지 비효율이 있다. 이것들을 제거하라
이 글에서 설명되는 두 개의 SQL은 길이가 매우 짧다. 그 중 하나는 비효율을 찾아내기 쉽고, 나머지 하나는 어렵다. 두 개의 SQL에는 총 5가지의 튜닝 포인트가 있다. 각각의 포인트는 20점이며 5가지를 모두 맞추는 경우는 100점이 된다. 채점 시 중요한 점은, 독자들이 직접 튜닝한 SQL이 모범답안과 같은지 비교하는 것이 아니라는 것이다. 그것 보다는 비효율을 몇 개 잡아내었는지, 또한 각각의 비효율을 개선시킬 수 있는 방법은 몇 개나 생각했는지를 채점하는 것이다. 이렇게 채점하면, 내가 아는 것은 무엇이고, 모르는 것은 무엇인지 명확히 드러난다. 즉, 무엇을 더 공부해야 하는지 알 수 있다.
다른 사람들은 몇 점 정도 받았나?
몇몇 지인들에게 퀴즈를 내본 결과 100점은 아무도 없었다. 즉 80점이 평균적인 튜너의 수준이라는 이야기 이다. 개발자의 경우는 60점이면 상위 수준이다. 점수에 대해 오해는 하지 말기 바란다. 이 퀴즈로 받은 점수는 분석함수의 성능과 관련된 것일 뿐, 전반적인 SQL 튜닝능력에 대한 점수가 아니다.
이제 실습을 위한 테이블과 인덱스를 생성하자. 실습환경은 Oracle 10g R2, Oracle 11g R1, Oracle 11g R2로 한정한다.
CREATE TABLE SALES_T NOLOGGING AS SELECT * FROM SALES;
ALTER TABLE SALES_T ADD CONSTRAINT PK_SALES_T
PRIMARY KEY (PROD_ID, CUST_ID, CHANNEL_ID, TIME_ID) USING INDEX;
개발자가 작성한 문제의 SQL 1
SELECT *
FROM ( SELECT /*+ INDEX(T PK_SALES_T) */ PROD_ID, CUST_ID, TIME_ID, CHANNEL_ID, AMOUNT_SOLD,
MAX(TIME_ID) OVER( PARTITION BY CUST_ID ,CHANNEL_ID ) AS MAX_TIME
FROM SALES_T T
WHERE PROD_ID = 30 )
WHERE TIME_ID = MAX_TIME;
업무설명 : 상품번호 30인 데이터에 대하여 고객별, 채널 별로 가장 최근의 판매량을 나타내시오.
단 고객별, 채널별로 가장 최근의 데이터는 2건 이상일 수 있음.
-----------------------------------------------------------------------------------------------
| Id | Operation | Name | A-Rows | A-Time | Buffers | Used-Mem |
-----------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 12649 |00:00:00.31 | 28337 | |
|* 1 | VIEW | | 12649 |00:00:00.31 | 28337 | |
| 2 | WINDOW BUFFER | | 29282 |00:00:00.27 | 28337 | 1495K (0)|
| 3 | TABLE ACCESS BY INDEX ROWID| SALES_T | 29282 |00:00:00.17 | 28337 | |
|* 4 | INDEX RANGE SCAN | PK_SALES_T | 29282 |00:00:00.03 | 118 | |
-----------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("TIME_ID"="MAX_TIME")
4 - access("PROD_ID"=30)
WHERE 절에 TIME_ID = MAX_TIME 이 존재하는 이유는 고객별, 채널별로 MAX(TIME_ID)에 해당하는 데이터가 두건 이상일 수 있기 때문이다. 이런 경우는 자주 발생한다. 이해를 돕기 위해 비슷한 예를 들어보자. 부서별로 최대급여를 받는 사람들을 출력하고자 할 때, 1번 부서의 최대급여는 1억 원이라고 하자. 그런데 그 부서에서 1억 원(최대급여)을 받는 사람은 강호동, 유재석 둘이라는 이야기 이다.
위의 SQL은 답이 정확하다. 하지만 성능은 비효율이 있어서 별로 신통치 못하다. 이제 문제를 보자. 위 SQL에 여전히 남아있는 비효율을 개선하는 것이 문제이다.
문제1) 위의 SQL 에서 성능상 문제점을 발견하고 개선하시오. 문제점은 두 가지(분석함수의 관점, 일반적인 SQL튜닝의 관점) 이다. 단 인덱스를 추가로 생성하거나 변경해서는 안 된다.
문제 1의 답안
비효율 1은 Sample 답안이다. 점수에 반영되지 않는다.
문제1의 비효율 1 : SALES_T 테이블에 Random Access가 불필요하게 많이 발생한다. 12649 번만 테이블로 액세스 하면 되지만 실제로는 29282 번 액세스함으로써 비효율이 발생되었다.
문제1의 비효율 1의 해결방법 : PK인덱스에 AMOUNT_SOLD가 포함되어 있지 않으므로 Select 절에서 AMOUNT_SOLD를 빼면 인덱스만 액세스 하게 됨. 이때 Rowid를 추가로 Select 해야 한다. 이후에 이미 인덱스에서 Filter된 Rowid로 테이블을 액세스하면 Random Access는 정확히 12649번 만 시도한다. 아래에 SQL이 있으므로 참조하시오.
문제1의 비효율1이 해결된 SQL과 실행계획 제시:
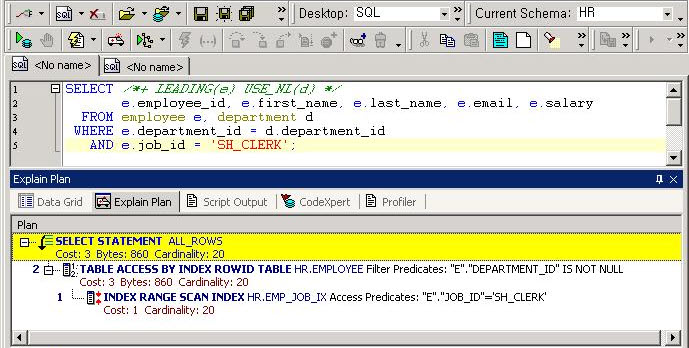
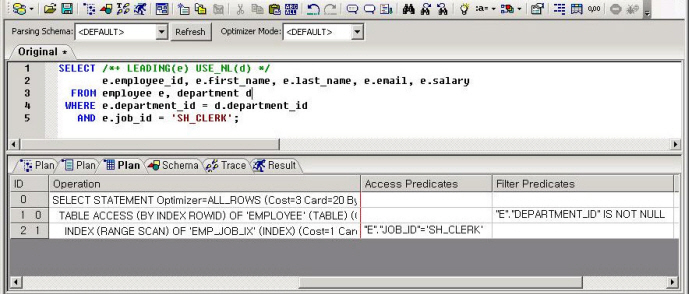
SELECT /*+ LEADING(S) USE_NL(S1) */
S.PROD_ID, S.CUST_ID, S.TIME_ID, S.CHANNEL_ID, S1.AMOUNT_SOLD
FROM ( SELECT /*+ INDEX(T PK_SALES_T) */ PROD_ID, CUST_ID, TIME_ID, CHANNEL_ID,
MAX(TIME_ID) OVER( PARTITION BY CUST_ID ,CHANNEL_ID ) AS MAX_TIME,
ROWID AS RID
FROM SALES_T T
WHERE PROD_ID = 30 ) S,
SALES_T S1
WHERE S.TIME_ID = S.MAX_TIME
AND S1.ROWID = S.RID;
------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | A-Rows | A-Time | Buffers | Used-Mem |
------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 12649 |00:00:02.72 | 11237 | |
| 1 | NESTED LOOPS | | 1 | 12649 |00:00:02.72 | 11237 | |
|* 2 | VIEW | | 1 | 12649 |00:00:00.18 | 118 | |
| 3 | WINDOW BUFFER | | 1 | 29282 |00:00:00.13 | 118 | 1432K (0)|
|* 4 | INDEX RANGE SCAN | PK_SALES_T | 1 | 29282 |00:00:00.03 | 118 | |
| 5 | TABLE ACCESS BY USER ROWID| SALES_T | 12649 | 12649 |00:00:02.48 | 11119 | |
------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("S"."TIME_ID"="S"."MAX_TIME")
4 - access("PROD_ID"=30)
이렇게 해서 Sample 답안을 작성해 보았다. 이 방법은 분석함수의 튜닝방법이 아니라 예외적으로 SQL 튜닝방법론에서 언급되었던 방법을 사용하였다. 물론 여기서 페이징처리를 한다면 추가적인 성능향상이 가능하지만 Sample이므로 여기서 멈추기로 한다. 위의 답안은 Sample 이므로 점수에서 빠진다. 또한 이 부분은 분석함수의 튜닝 방법이 아니다. 하지만 앞으로 풀게 될 문제들은 모두 분석함수와 관련된 문제들이다.
문제1의 비효율 2
비효율 1을 제거하니 Random Access는 최소화 되었다. 하지만 실행계획을 보면 쓸데없이 PGA를 1432K만큼 사용하고 있다. 즉 불필요한 WINDOW BUFFER Operation 때문에 sort가 발생하였다.
문제1의 비효율 2 해결방법
고객별 채널별로 최종일자의 데이터를 구하는 것이므로, Rank를 사용하면 적절한 인덱스가 존재하므로 sort를 하지 않는다. Rank는 Row_number와는 다르게 1등이 두 명 이상일 수 있으므로 업무조건을 만족한다.
문제1의 비효율 2이 해결된 SQL과 실행계획 제시.
SELECT /*+ LEADING(A) USE_NL(B) */ A.*, B.AMOUNT_SOLD
FROM ( SELECT /*+ INDEX_DESC(T PK_SALES_T) */ PROD_ID, CUST_ID, TIME_ID, CHANNEL_ID,
RANK() OVER(PARTITION BY CUST_ID, CHANNEL_ID ORDER BY TIME_ID DESC) RNK,
ROWID AS RID
FROM SALES_T T
WHERE PROD_ID = 30 ) A,
SALES_T B
WHERE A.RNK = 1
AND A.RID = B.ROWID;
---------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | A-Rows | A-Time | Buffers | Used-Mem |
---------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 12649 |00:00:00.32 | 11240 | |
| 1 | NESTED LOOPS | | 1 | 12649 |00:00:00.32 | 11240 | |
|* 2 | VIEW | | 1 | 12649 |00:00:00.20 | 120 | |
|* 3 | WINDOW NOSORT | | 1 | 29282 |00:00:00.16 | 120 | |
|* 4 | INDEX RANGE SCAN DESCENDING| PK_SALES_T | 1 | 29282 |00:00:00.06 | 120 | |
| 5 | TABLE ACCESS BY USER ROWID | SALES_T | 12649 | 12649 |00:00:00.05 | 11120 | |
---------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("A"."RNK"=1)
3 - filter(RANK() OVER ( PARTITION BY "CUST_ID","CHANNEL_ID" ORDER BY INTERNAL_FUNCTION("TIME_ID") DESC )<=1)
4 - access("PROD_ID"=30)
이제 문제2를 풀어보자.
개발자가 작성한 문제의 SQL 2
SELECT *
FROM ( SELECT /*+ INDEX(T PK_SALES_T) */ PROD_ID, CUST_ID, TIME_ID, CHANNEL_ID, AMOUNT_SOLD,
ROW_NUMBER() OVER ( PARTITION BY PROD_ID ORDER BY CUST_ID,CHANNEL_ID,TIME_ID NULLS FIRST) AS RN,
SUM(AMOUNT_SOLD) OVER ( ORDER BY CUST_ID,CHANNEL_ID,TIME_ID,PROMO_ID ) AS SUM_AMT
FROM SALES_T T
WHERE PROD_ID = 30 )
WHERE RN <= 10 ;
---------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | A-Rows | A-Time | Buffers | Used-Mem |
---------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 10 |00:00:00.43 | 28337 | |
|* 1 | VIEW | | 1 | 10 |00:00:00.43 | 28337 | |
|* 2 | WINDOW SORT PUSHED RANK | | 1 | 29282 |00:00:00.40 | 28337 | 1999K (0)|
| 3 | WINDOW SORT | | 1 | 29282 |00:00:00.30 | 28337 | 1684K (0)|
| 4 | TABLE ACCESS BY INDEX ROWID| SALES_T | 1 | 29282 |00:00:00.18 | 28337 | |
|* 5 | INDEX RANGE SCAN | PK_SALES_T | 1 | 29282 |00:00:00.04 | 118 | |
---------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("RN"<=10)
2 - filter(ROW_NUMBER() OVER ( PARTITION BY "PROD_ID" ORDER BY "CUST_ID","CHANNEL_ID",INTERNAL_FUNCTION("TIME_ID")
NULLS FIRST)<=10)
5 - access("PROD_ID"=30)
문제2) 위의 SQL 에서 분석함수의 성능상 문제점을 발견하고 개선하시오. 분석함수와 관련된 성능상 문제점은 4가지 이다. 비효율들을 발견하고 이를 모두 개선해야 한다. 단 인덱스를 추가로 생성하거나 변경하면 안 된다.
문제 2의 답안
문제2의 비효율 1
NULLS FIRST를 사용하면 인덱스를 Ascending으로 사용하면 null 값은 가장 마지막에 출력된다. 즉 null 값이 마치 가장 큰 값인 것처럼 저장 되는 것이다. 하지만 NULLS FIRST를 명시하는 순간 sort가 뒤바뀌어 가장 먼저 출력해야 한다. 즉 인덱스를 사용했지만 NULLS FIRST 때문에 추가적인 sort가 필요하다는 이야기 이다. 이러한 문제는 인덱스를 Descending 하게 사용할 때, NULLS LAST를 명시해도 똑같이 발생한다.
문제2의 비효율 1 해결방법
문제의 SQL을 보면 PARTITION BY나 ORDER BY의 컬럼들은 PK 컬럼들이므로 null 일수 없다. 따라서 NULLS FIRST를 삭제해도 무방하다. 다시 작성한 SQL은 다음과 같다.
문제2의 비효율 1이 해결된 SQL과 실행계획 제시
SELECT *
FROM ( SELECT /*+ INDEX(T PK_SALES_T) */ PROD_ID, CUST_ID, TIME_ID, CHANNEL_ID, AMOUNT_SOLD,
ROW_NUMBER() OVER (PARTITION BY PROD_ID ORDER BY CUST_ID,CHANNEL_ID,TIME_ID ) AS RN,
SUM(AMOUNT_SOLD) OVER ( ORDER BY CUST_ID,CHANNEL_ID,TIME_ID,PROMO_ID ) AS SUM_AMT
FROM SALES_T T
WHERE PROD_ID = 30 )
WHERE RN <= 10 ;
---------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | A-Rows | A-Time | Buffers | Used-Mem |
---------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 10 |00:00:00.45 | 28337 | |
|* 1 | VIEW | | 1 | 10 |00:00:00.45 | 28337 | |
|* 2 | WINDOW NOSORT | | 1 | 29282 |00:00:00.42 | 28337 | |
| 3 | WINDOW SORT | | 1 | 29282 |00:00:00.32 | 28337 | 1684K (0)|
| 4 | TABLE ACCESS BY INDEX ROWID| SALES_T | 1 | 29282 |00:00:00.17 | 28337 | |
|* 5 | INDEX RANGE SCAN | PK_SALES_T | 1 | 29282 |00:00:00.03 | 118 | |
---------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("RN"<=10)
2 - filter(ROW_NUMBER() OVER ( PARTITION BY "PROD_ID" ORDER BY "CUST_ID","CHANNEL_ID","TIME_ID")<=10)
5 - access("PROD_ID"=30)
ROW_NUMBER에 해당하는 Operation이 WINDOW SORT PUSHED RANK에서 WINDOW NOSORT로 바뀌었다. 그 영향으로 ROW_NUMBER는 Sort가 전혀 발생하지 않는다.
문제2의 비효율 2
비효율 1의 튜닝의 결과를 놓고 보면, ROW_NUMBER와 SUM 분석함수의 Operation이 실행계획에 각각 존재한다. 즉 분석함수가 따로 따로 두 번 실행되는 것이다. 분석함수의 종류는 두 개(row_number와 sum)라 하더라도, 분석함수와 관련된 Operation이 한번만 나와야 한다는 말이다. 또한 분석함수 SUM의 order by절에 PROMO_ID가 존재하여 불필요한 sort가 발생하였다.
문제2의 비효율 2 해결방법
이 비효율을 없애면 마치 분석함수가 하나뿐인 것처럼 만들 수 있다. Partition 절과 Order 절을 일치시키면 된다. 아래의 SQL은 Partition 절과 Order 절을 일치시키기 위해 SUM 분석함수에 PARTITION BY 절을 추가해야 한다. 물론 ROW_NUMBER함수에서 Partition By절을 삭제할 수 있지만, 그와 관련된 이야기는 이후 단계에서 논의 되므로, 여기서는 그냥 Partition By절을 추가하기로 한다. 그리고 WINDOW SORT를 유발하는 PROMO_ID도 삭제해야 한다.
문제2의 비효율 2가 해결된 SQL과 실행계획 제시
SELECT *
FROM ( SELECT /*+ INDEX(T PK_SALES_T) */ PROD_ID, CUST_ID, TIME_ID, CHANNEL_ID, AMOUNT_SOLD,
ROW_NUMBER() OVER (PARTITION BY PROD_ID ORDER BY CUST_ID,CHANNEL_ID,TIME_ID ) AS RN,
SUM(AMOUNT_SOLD) OVER (PARTITION BY PROD_ID ORDER BY CUST_ID,CHANNEL_ID,TIME_ID ) AS SUM_AMT
FROM SALES_T T
WHERE PROD_ID = 30 )
WHERE RN <= 10 ;
--------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | A-Rows | A-Time | Buffers | Used-Mem |
--------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 10 |00:00:00.26 | 28337 | |
|* 1 | VIEW | | 1 | 10 |00:00:00.26 | 28337 | |
| 2 | WINDOW BUFFER | | 1 | 29282 |00:00:00.23 | 28337 | 1495K (0)|
| 3 | TABLE ACCESS BY INDEX ROWID| SALES_T | 1 | 29282 |00:00:00.11 | 28337 | |
|* 4 | INDEX RANGE SCAN | PK_SALES_T | 1 | 29282 |00:00:00.03 | 118 | |
--------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("RN"<=10)
4 - access("PROD_ID"=30)
만약 해결방법 두 가지(Partition By 추가, PROMO_ID 삭제)중 한가지만 적용했다면 10점으로 처리하면 되므로 채점은 가능하다. 아래의 설명부분과 SQL은 답안이 아니며, 원리를 설명하는 부분이다.
Operation 통합의 원리
분석함수 SUM에 Partition By절을 추가하고, order by절에 PROMO_ID를 삭제하니, 예상대로 분석함수 두 개의 Plan이 하나로 합쳐졌다. 여기서 알 수 있는 점은 두 가지 이다. 첫 번째, Partition By와 Order By를 통일 시키면 Operation이 통합되어 분석함수 하나만 실행시키는 결과를 얻는다. 두 번째, WINDOW NOSORT(ROW_NUMBER) + WINDOW BUFFER(SUM) 가 합쳐져서 WINDOW BUFFER가 되었다는 점이다. 좋지 않은 Operation으로 통합된다는 것을 알 수 있다. 기준은 다음과 같다.
WINDOW NOSORT + WINDOW SORT => WINDOW SORT
WINDOW NOSORT + WINDOW BUFFER => WINDOW BUFFER
WINDOW BUFFER + WINDOW SORT => WINDOW SORT
PROMO_ID를 삭제해도 되는 이유는 ORDER BY에서 모든 PK 컬럼을 사용하였기 때문이다. 즉 PK 컬럼들로 ORDER BY절에서 모두 SORT 되었으므로, 나머지 컬럼으로 아무리 SORT 해보아야 결과는 동일하다는 것이다. Order By절에서 PROMO_ID를 삭제하자 WINDOW SORT가 WINDOW BUFFER 로 바뀌었다. 이에 따라 PGA사용량이 1747K에서 1495K 약간 줄어들었다.
만약 Partition By만 추가하고 PROMO_ID를 삭제하지 않으면 아래와 같이 sort의 비효율이 발생한다.
SELECT *
FROM ( SELECT /*+ INDEX(T PK_SALES_T) */ PROD_ID, CUST_ID, TIME_ID, CHANNEL_ID, AMOUNT_SOLD,
ROW_NUMBER() OVER (PARTITION BY PROD_ID ORDER BY CUST_ID,CHANNEL_ID,TIME_ID ) AS RN,
SUM(AMOUNT_SOLD) OVER (PARTITION BY PROD_ID ORDER BY CUST_ID,CHANNEL_ID,TIME_ID,PROMO_ID ) AS SUM_AMT
FROM SALES_T T
WHERE PROD_ID = 30 )
WHERE RN <= 10 ;
--------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | A-Rows | A-Time | Buffers | Used-Mem |
--------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 10 |00:00:00.33 | 28337 | |
|* 1 | VIEW | | 1 | 10 |00:00:00.33 | 28337 | |
| 2 | WINDOW SORT | | 1 | 29282 |00:00:00.30 | 28337 | 1747K (0)|
| 3 | TABLE ACCESS BY INDEX ROWID| SALES_T | 1 | 29282 |00:00:00.17 | 28337 | |
|* 4 | INDEX RANGE SCAN | PK_SALES_T | 1 | 29282 |00:00:00.03 | 118 | |
--------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("RN"<=10)
4 - access("PROD_ID"=30)
Order By절이 다르지만, 통합이 가능한 이유
PROMO_ID를 추가하자, WINDOW SORT가 발생하여 PGA 사용량이 늘어났다. 분석함수 SUM의 ORDER BY절을 보면 PROMO_ID가 있는데 ROW_NUMBER 분석함수에는 PROMO_ID가 없다. ORDER BY는 완벽히 같지 않아도 Operation이 통합 될 수 있다는 점을 알 수 있다. ORDER BY의 마지막 항목이 달라도 Operation이 통합 될 수 있는 원리는 간단하다. Sort 작업을 A + B + C로 이미 했다면 Sort를 A + B 로 다시 해야 할 필요가 없기 때문이다. 즉 A + B + C로 Sort 하는 분석함수 기준으로 A + B로 Sort 하는 분석함수가 통합된다는 의미이다.
오해하지 말 것
서로 다른 종류의 분석함수를 실행했을 때, Partition By의 컬럼과 Order By의 컬럼을 각각 똑같이 맞추어야 하는 것은 아니다. Partition By나 Order By의 컬럼을 각각 맞추는 것이 아니라, OVER절 전체의 컬럼을 일치시키면 된다. 아래의 SQL이 좋은 예제이다.
SELECT *
FROM ( SELECT /*+ INDEX(T PK_SALES_T) */ PROD_ID, CUST_ID, TIME_ID, CHANNEL_ID, AMOUNT_SOLD,
ROW_NUMBER() OVER (PARTITION BY PROD_ID ORDER BY CUST_ID, CHANNEL_ID,TIME_ID ) AS RN,
SUM(AMOUNT_SOLD) OVER (PARTITION BY PROD_ID, CUST_ID ORDER BY CHANNEL_ID,TIME_ID ) AS SUM_AMT
FROM SALES_T T
WHERE PROD_ID = 30 )
WHERE RN <= 10 ;
--------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | A-Rows | A-Time | Buffers | Used-Mem |
--------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 10 |00:00:00.32 | 28337 | |
|* 1 | VIEW | | 1 | 10 |00:00:00.32 | 28337 | |
| 2 | WINDOW BUFFER | | 1 | 29282 |00:00:00.28 | 28337 | 1495K (0)|
| 3 | TABLE ACCESS BY INDEX ROWID| SALES_T | 1 | 29282 |00:00:00.14 | 28337 | |
|* 4 | INDEX RANGE SCAN | PK_SALES_T | 1 | 29282 |00:00:00.04 | 118 | |
--------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("RN"<=10)
4 - access("PROD_ID"=30)
위의 SQL을 보면 분석함수 두 개의 Partition By의 컬럼과 Order By 컬럼이 모두 다르다. 하지만 실행계획상의 operation은 하나로 통합되었다. 즉 OVER절을 바라볼 때 Partition By나 Order By를 삭제하고 컬럼들만 남긴다면, operation이 통합이 될지, 아닐지 판단할 수 있다. 예컨대, over절의 컬럼은 두 개의 분석함수 모두 PROD_ID + CUST_ID + CHANNEL_ID + TIME_ID 로 똑같으므로 operation이 통합된다.
중요한 것은 컬럼의 순서이다. 즉 Partition By나 Order By를 삭제하고 순수하게 over절의 컬럼들만 남겼을 때, 컬럼의 순서가 같아야 operation이 통합된다. 컬럼의 순서가 다르면 통합되지 않는다. 위의 분석함수 둘은 over절의 컬럼순서가 PROD_ID + CUST_ID + CHANNEL_ID + TIME_ID로 같음을 알 수 있다. OVER절 전체의 컬럼순서가 같다면, 컬럼의 개수와는 상관없이 통합이 가능하다. 예를 들어, 분석함수를 두 개 사용하고 컬럼순서가 하나는 A+B+C 이고 다른 하나는 A+B 라면, 컬럼순서가 동일하므로 통합이 가능하다. 하지만 A+B+C 와 A+C의 조합은 컬럼순서가 다르므로 통합이 불가능하다.
문제2의 비효율 3
비효율 2의 튜닝결과를 보면 Ranking family를 사용하고, 인라인뷰 외부에서 분석함수를 Filter로 처리했음에도 불구하고 STOPKEY가 작동하지 않는다. 이에 따라 부분범위처리가 되지 못하고 불필요한 데이터를 모두 Scan해야 한다.
문제2의 비효율 3의 해결방법
STOPKEY가 작동되도록 하려면 ROW_NUMBER의 OVER절에서 불필요한 PARTITION BY PROD_ID를 제거하면 된다. PROD_ID는 이미 WHERE 절의 Equal 조건에 의하여 상수화 되었기 때문에 PARTITION BY는 필요 없다.
문제2의 비효율 3이 해결된 SQL과 실행계획 제시
SELECT *
FROM ( SELECT /*+ INDEX(T PK_SALES_T) */ PROD_ID, CUST_ID, TIME_ID, CHANNEL_ID, AMOUNT_SOLD,
ROW_NUMBER() OVER ( ORDER BY CUST_ID,CHANNEL_ID,TIME_ID ) AS RN,
SUM(AMOUNT_SOLD) OVER (PARTITION BY PROD_ID ORDER BY CUST_ID,CHANNEL_ID,TIME_ID ) AS SUM_AMT
FROM SALES_T T
WHERE PROD_ID = 30 )
WHERE RN <= 10 ;
---------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | A-Rows | A-Time | Buffers | Used-Mem |
---------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 10 |00:00:00.16 | 28337 | |
|* 1 | VIEW | | 1 | 10 |00:00:00.16 | 28337 | |
|* 2 | WINDOW NOSORT STOPKEY | | 1 | 10 |00:00:00.16 | 28337 | |
| 3 | WINDOW BUFFER | | 1 | 11 |00:00:00.16 | 28337 | 1495K (0)|
| 4 | TABLE ACCESS BY INDEX ROWID| SALES_T | 1 | 29282 |00:00:00.11 | 28337 | |
|* 5 | INDEX RANGE SCAN | PK_SALES_T | 1 | 29282 |00:00:00.03 | 118 | |
---------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("RN"<=10)
2 - filter(ROW_NUMBER() OVER ( ORDER BY "CUST_ID","CHANNEL_ID","TIME_ID")<=10)
5 - access("PROD_ID"=30)
아래의 설명부분과 SQL은 답안이 아니며 원리를 설명하는 부분이다.
Ranking family에서 불필요한 Partition By를 삭제하자 WINDOW NOSORT STOPKEY가 발생되었다. 하지만 실행계획을 자세히 보면 비효율이 존재한다. 즉 WINDOW BUFFER 때문에 29282건을 모두 읽은 후에 STOPKEY가 발생되었다. 처음부터 11건만 읽는 방법은 없는 것일까? 그렇다고 위의 SQL에서 분석함수 SUM의 PARTITION BY도 삭제한다면 비효율 2의 실행계획으로 돌아가 버린다. 비효율 2에서 이미 설명했던 원칙(좋지 않은 Operation으로 통합되는 원칙) 때문에 WINDOW NOSORT STOPKEY가 WINDOW BUFFER에 묻혀버리는 것이다.
만약 WINDOW BUFFER(분석함수 SUM)가 없다면 WINDOW NOSORT STOPKEY가 완벽히 동작한다. 아래의 SQL로 증명할 수 있다.
SELECT *
FROM ( SELECT /*+ INDEX(T PK_SALES_T) */ PROD_ID, CUST_ID, TIME_ID, CHANNEL_ID, AMOUNT_SOLD,
ROW_NUMBER() OVER ( ORDER BY CUST_ID,CHANNEL_ID,TIME_ID ) AS RN
FROM SALES_T T
WHERE PROD_ID = 30 )
WHERE RN <= 10 ;
--------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | A-Rows | A-Time | Buffers | Used-Mem |
--------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 10 |00:00:00.01 | 15 | |
|* 1 | VIEW | | 1 | 10 |00:00:00.01 | 15 | |
|* 2 | WINDOW NOSORT STOPKEY | | 1 | 10 |00:00:00.01 | 15 | |
| 3 | TABLE ACCESS BY INDEX ROWID| SALES_T | 1 | 11 |00:00:00.01 | 15 | |
|* 4 | INDEX RANGE SCAN | PK_SALES_T | 1 | 11 |00:00:00.01 | 4 | |
--------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("RN"<=10)
2 - filter(ROW_NUMBER() OVER ( ORDER BY "CUST_ID","CHANNEL_ID","TIME_ID")<=10)
4 - access("PROD_ID"=30)
분석함수 SUM만 제거한다면 STOPKEY가 비효율 없이 작동하여 정확히 11건만 읽었다. 위의 실행통계와 비효율 3이 튜닝된 SQL의 실행통계를 비교해보라. Buffers와 Used-Mem 항목을 본다면 비교할 수 없을 정도이다. 또한 WINDOW STOPKEY의 활용범위는 ROWNUM 보다 넓다. 물론 ROW_NUMBER는 ROWNUM 처럼 사용 할 수도 있다. 하지만, RANK나 DENSE_RANK의 경우로 본다면 추가적인 활용법이 있다. 예를 들어, 학교에서 수학성적으로 전교석차 2등 까지 출력한다고 치자. 그러면 1등과 2등이 각각 두 명 이상일 수 있다. 이런 경우는 ROWNUM으로는 구현할 수 없다. RANK나 DENSE_RANK가 WINDOW NOSORT STOPKEY로 성능을 충족시켜면서, 업무요구사항을 만족시키는 유일한 방법이다.
Sort량 2K vs 1999K의 비밀
SELECT *
FROM (SELECT /*+ INDEX(T PK_SALES_T) */
PROD_ID, CUST_ID, TIME_ID, CHANNEL_ID, AMOUNT_SOLD,
ROW_NUMBER () OVER (ORDER BY CUST_ID, CHANNEL_ID, TIME_ID NULLS FIRST) AS RN,
SUM (AMOUNT_SOLD) OVER (ORDER BY CUST_ID, CHANNEL_ID, TIME_ID, PROMO_ID) AS SUM_AMT
FROM SALES_T T
WHERE PROD_ID = 30)
WHERE RN <= 10 ;
---------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | A-Rows | A-Time | Buffers | Used-Mem |
---------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 10 |00:00:00.34 | 28337 | |
|* 1 | VIEW | | 1 | 10 |00:00:00.34 | 28337 | |
|* 2 | WINDOW SORT PUSHED RANK | | 1 | 11 |00:00:00.34 | 28337 | 2048 (0)|
| 3 | WINDOW SORT | | 1 | 29282 |00:00:00.30 | 28337 | 1684K (0)|
| 4 | TABLE ACCESS BY INDEX ROWID| SALES_T | 1 | 29282 |00:00:00.18 | 28337 | |
|* 5 | INDEX RANGE SCAN | PK_SALES_T | 1 | 29282 |00:00:00.04 | 118 | |
---------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("RN"<=10)
2 - filter(ROW_NUMBER() OVER ( ORDER BY "CUST_ID","CHANNEL_ID",INTERNAL_FUNCTION("TIME_ID") NULLS FIRST)<=10)
5 - access("PROD_ID"=30)
위의 SQL은 개발자가 작성한 원본 SQL에서 ROW_NUMBER 함수의 Partition By절을 삭제하고 실행한 것이다. 이 경우는 over절의 NULLS FIRST 때문에 Sort가 발생되는 경우이다. 이 때에도 Sort가 최소화 되어 PGA 사용량은 2K에 불과하다. 개발자가 작성한 원본 실행통계의 Sort량이 1999K임을 감안하면 Partition By의 존재유무는 성능에 지대한 영향을 끼친다고 할 수 있다. Sort량이 이렇게 큰 차이가 나는 이유는 파티션을 삭제한 효과 + RN <= 10 조건 때문이다. 그 filter 조건에 의해서 10개의 배열만 관리하면 되므로 PGA 사용량은 최소화 된다. WINDOW SORT PUSHED RANK의 이러한 성격은 인덱스를 사용하지 않는 경우에도 동일하게 나타난다. 위의 SQL에서 힌트를 FULL(T)로 바꾸고 실행하여도 PGA 사용량은 동일하다.
위의 SQL 처럼 ROW_NUMBER 함수의 NULLS FIRST 보다 Partition By절을 먼저 삭제한 사람은 이 원리를 답안으로 사용해도 무방하다. 하지만 비효율 3에서 설명되었던, Partition By 삭제에 의한 NOSORT STOPKEY 유도 원리는 WINDOW SORT PUSHED RANK와 성격이 다르므로 반드시 알아두어야 한다.
문제2의 비효율 4
진퇴양란, 포기할 것인가?
비효율 3의 튜닝결과를 보면 STOPKEY를 발생시키려고 ROW_NUMBER의 Partition By를 제거하니 Operation이 두 개로 분리되어 다시 비효율이 발생하였다. 그렇다고 분석함수 SUM을 삭제하자니 업무요구사항이 만족되지 않는다. 어떻게든 STOPKEY를 발생시켜서 29282건을 모두 읽는 비효율을 제거해야 한다.
분석함수 SUM을 삭제하는 것은 답이 아니다
보통 이런 경우(진퇴양란)에서는 둘 중에 한가지를 선택한다. 튜닝을 포기하거나 장애물을 제거한다. 열정이 있는 개발자들은 장애물을 제거할 것이다. 분석함수 SUM을 삭제하고, 조회화면에서 프로그램 스크립트를 작성하여 분석함수 SUM의 로직을 대신한다. 물론 이렇게 하는 것은 목적을 달성하는 것이므로, 포기하는 것보다는 만족스럽다. 하지만 나는 포기하지도 말고, 프로그래밍 언어의 도움도 받지 말라고 주장한다. SQL이 아닌 다른 언어의 도움으로 비효율을 해결한 것은 이 문제의 정답이 아니며, SQL만으로 해결할 수 있다.
문제2의 비효율 4 해결방법
일부 개발자는 분석함수 SUM을 제거하고 프로그래밍 언어의 도움을 받아 해결하였다. 하지만 우리는 분석함수 SUM을 물리적으로 삭제하는 것이 아니라 실행계획상에서만 삭제하고자 한다. 방법은 SUM/MIN/MAX/AVG 등의 분석함수에 WINDOW의 범위를 명시적으로 작성하면 된다. 물론 범위를 명시적으로 작성해도 답은 동일하다.
문제2의 비효율 4가 해결된 SQL과 실행계획 제시
SELECT *
FROM ( SELECT /*+ INDEX(T PK_SALES_T) */ PROD_ID, CUST_ID, TIME_ID, CHANNEL_ID, AMOUNT_SOLD,
ROW_NUMBER() OVER (ORDER BY CUST_ID,CHANNEL_ID,TIME_ID ) AS RN,
SUM(AMOUNT_SOLD) OVER (ORDER BY CUST_ID,CHANNEL_ID,TIME_ID
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW ) AS SUM_AMT
FROM SALES_T T
WHERE PROD_ID = 30 )
WHERE RN <= 10 ;
--------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | A-Rows | A-Time | Buffers | Used-Mem |
--------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 10 |00:00:00.01 | 15 | |
|* 1 | VIEW | | 1 | 10 |00:00:00.01 | 15 | |
|* 2 | WINDOW NOSORT STOPKEY | | 1 | 10 |00:00:00.01 | 15 | |
| 3 | TABLE ACCESS BY INDEX ROWID| SALES_T | 1 | 11 |00:00:00.01 | 15 | |
|* 4 | INDEX RANGE SCAN | PK_SALES_T | 1 | 11 |00:00:00.01 | 4 | |
--------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("RN"<=10)
2 - filter(ROW_NUMBER() OVER ( ORDER BY "CUST_ID","CHANNEL_ID","TIME_ID")<=10)
4 - access("PROD_ID"=30)
분석함수 SUM을 제거한 것은 아니지만, WINDOW의 범위를 주어 동일한 효과를 얻었다. 정확히 11건만 읽었으므로, 깔끔하게 모든 문제가 정리되었다. Window의 범위를 명시적으로 작성하는 것이 얼마나 중요한지 알 수 있다.
여기까지가 답안이다. 이제 어떻게 된 것인지 알아보기 위해 분석함수 ROW_NUMBER를 삭제해 보자.
SELECT *
FROM ( SELECT /*+ INDEX(T PK_SALES_T) */ PROD_ID, CUST_ID, TIME_ID, CHANNEL_ID, AMOUNT_SOLD,
SUM(AMOUNT_SOLD) OVER (ORDER BY CUST_ID,CHANNEL_ID,TIME_ID
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW ) AS SUM_AMT
FROM SALES_T T
WHERE PROD_ID = 30 ) ;
--------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | A-Rows | A-Time | Buffers | Used-Mem |
--------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 29282 |00:00:00.36 | 28340 | |
| 1 | VIEW | | 1 | 29282 |00:00:00.36 | 28340 | |
| 2 | WINDOW NOSORT | | 1 | 29282 |00:00:00.30 | 28340 | |
| 3 | TABLE ACCESS BY INDEX ROWID| SALES_T | 1 | 29282 |00:00:00.20 | 28340 | |
|* 4 | INDEX RANGE SCAN | PK_SALES_T | 1 | 29282 |00:00:00.03 | 121 | |
--------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
4 - access("PROD_ID"=30)
그룹분석함수와 Ranking Family를 같이 사용해도 STOPKEY가 발생한다
그룹분석함수임에도 SORT가 전혀 발생하지 않았다. 즉 SUM/MIN/MAX/AVG 등의 분석함수에 WINDOW의 범위를 지정해주면 WINDOW BUFFER가 WINDOW NOSORT로 바뀐다는 이야기 이다. 이것은 의미 있는 발견이다. 왜냐하면 이때 까지는 SUM/MIN/MAX/AVG 등의 분석함수 때문에 적절한 인덱스를 사용하였지만 WINDOW BUFFER가 발생하여 STOPKEY를 발생시키지 못했다. 그런데 이제 WINDOW NOSORT가 가능해짐으로 Ranking Family의 STOPKEY가 정상적으로 작동하기 때문이다.
이제 적절한 인덱스가 있고, SUM등의 그룹분석함수를 사용한다면, 다음과 같은 결론을 내릴 수 있다.
분석함수를 만날 때의 자세
2번 문제의 원본 SQL는 매우 짧은 코드이지만, 비효율은 4개나 된다. 튜닝을 완료했다고 자신하는 순간이라도, 마지막 남은 분석함수의 비효율 하나 때문에 SQL의 성능향상은 도루묵이 될 수 있다. 이런 사실은 SQL을 튜닝 할 때, 분석함수를 만나면 안테나를 세워야 하는 이유가 된다.
미래지향
다섯 가지 비효율에 대해 80점 혹은 그 이상을 받은 사람은 분석함수에 관한 튜닝은 상당한 수준에 있다고 생각한다. 반대로, 80점이 안 된다고 실망하지 말자. 왜냐하면 퀴즈에서 실패했더라도, 실무튜닝에서 100점을 받으면 그만이다. 물론 이렇게 되려면, SQL과 실행계획을 보고 비효율을 읽어내는 능력이 필요하다.
마지막으로 다섯 가지의 원리로 이 글 전부를 정리 해보자. 다섯 가지의 원리는 대부분 아래의 구조로 되어있다.
1) 소제목
2) ~ 를 하라.
3) 그렇게 하면 ~ 효과가 있다.
분석함수의 성능향상 원리
1. min/max 분석함수를 Ranking family로 대체하는 원리
적절한 인덱스를 사용하면서, 최종일자에 해당하는 데이터를 구할 때, MAX(최종일자) 분석함수를 사용하지 말고 Ranking family를 사용하라. 그렇게 하면 WINDOW BUFFER를 WINDOW NOSORT로 바꾸어 sort를 방지한다.
2. sort의 기준을 유지하는 원리
적절한 인덱스가 존재하는 경우, 분석함수의 ORDER BY절에 NULL FIRST나 LAST를 삭제할 수 있는지 검토하라. 그렇게 하면 인덱스 사용에 의한 Sort 기준이 유지되므로, 추가적인 sort를 방지한다. 주의사항은 NULL FIRST나 LAST를 사용한다고 해서 항상 Sort의 기준이 바뀌는 것은 아니며, 아래의 경우만 해당한다.
ex1) Index ASC로 사용 + 분석함수의 ORDER BY절에 NULL FIRST 는 추가적인 sort발생
ex2) Index DESC로 사용 + 분석함수의 ORDER BY절에 NULL LAST 는 추가적인 sort발생
3. 여러 개의 분석함수를 하나의 Operation으로 통합하는 원리
적절한 인덱스가 존재하고, 분석함수를 여러 개 사용할 때, 가능하면 OVER절의 Partition By와 Order By절을 일치시켜라. 그렇게 하면 여러 개의 OPERATION이 통합된다. 다시 말해, 분석함수를 하나만 실행하는 효과를 얻어서 실행시간을 단축시킨다. 이때 ORDER BY는 완전히 같지 않아도 Operation은 통합될 수 있다. 단 아래와 같이 좋지 않은 Operation 을 기준으로 통합된다.
ex1) WINDOW NOSORT + WINDOW SORT => WINDOW SORT
ex2) WINDOW NOSORT + WINDOW BUFFER => WINDOW BUFFER
ex3) WINDOW BUFFER + WINDOW SORT => WINDOW SORT
ORDER BY가 다를 때, Operation이 통합될 수 있는 조건이 있다. 그 세부내용은 본문을 참조하라.
4. Ranking Family를 이용한 TOP SQL에서 Sort 최소화의 원리
Ranking Family 분석함수를 인라인뷰 외부에서 Rownum 처럼 Filter로 사용했을 때, 불필요한 Partition By절을 삭제하라. 그렇게 하면 두 가지 경우에 성능이 향상된다. 주의사항은 Partition By절 전체를 제거해야 한다는 것이다. 만약 Partition By절에 컬럼이 하나라도 있으면 Sort가 대량으로 발생된다. 각각의 파티션 값마다 sort를 해야 하므로 어쩔 수 없는 일이다.
첫 번째, 적절한 인덱스가 없어서 FULL SCAN을 하거나 혹은 OVER절의 NULL FIRST나 LAST등의 원인으로 sort가 발생될 때 이다. 이럴 경우 Partition By을 제거하면 필요한 개수 + 1 만큼만 sort가 발생하므로 성능이 향상된다. 하지만 Rownum과는 달리 STOPKEY가 발생되지 않으므로 비효율은 존재한다. 이 때 발생되는 Operation은 WINDOW SORT PUSHED RANK 이다.
두 번째, 적절한 인덱스가 있어서 sort가 발생되지 않는 경우이다. 이 경우는 첫 번째의 경우와는 달리 sort가 전혀 발생하지 않으며, Rownum 처럼 STOPKEY를 발생시켜 부분범위 처리의 효과를 얻는다. 다시 말해, 분석함수를 Rownum 처럼 사용할 수 있다. 이 때 발생되는 Operation은 WINDOW NOSORT STOPKEY 이다. 이 기능은 10g R2에서 추가 되었다.
WINDOW NOSORT STOPKEY는 주의사항이 있다. 그룹분석함수의 OVER절과 Ranking Family의 OVER절의 컬럼순서가 다르면 Operation이 하나로 통합되지 못한다. 이 경우는 성능이 저하된다. 왜냐하면 WINDOW SORT 혹은 WINDOW BUFFER 가 먼저 실행되고 그 후에 WINDOW NOSORT STOPKEY가 발생하기 때문에 Block I/O나 sort량을 감소시키지 못한다. 이런 비효율 때문에 분석함수 여러 개를 하나의 Operation으로 통합하는 원리(원리 3번)의 역할이 중요한 것이다. 이와 관련된 예제는 비효율3이 해결된 SQL과 실행계획을 참조하기 바란다.
5. 그룹분석함수의 NO-SORT 원리
이 원리는 장점이 두 가지 이다. Sort를 방지하고, STOPKEY를 작동시킨다.
적절한 인덱스가 존재하고, sum/min/max/avg등의 Group 분석함수를 사용할 경우 명시적으로 WINDOW의 범위를 지정하라. 그렇게 하면 WINDOW BUFFER Operation을 WINDOW NOSORT로 바꾸어 불필요한 sort를 방지한다. 물론 여기서 이야기 하는 그룹분석함수는 현재 row 까지의 누적집계(Cumulative total) 이다.
더욱 좋은 것은, Ranking family를 Rownum 처럼 사용하고 있다면, STOPKEY를 사용할 수 있게 한다. 즉 Group 분석함수를 사용하면, WINDOW BUFFER가 발생하고, sort가 발생되는데, 이 때문에 STOPKEY를 작동 시킬 수 없다. 그런데 WINDOW의 범위를 지정하여 WINDOW NOSORT로 바꾸면 sort가 발생하지 않기 때문에 STOPKEY가 작동한다. WINDOW의 범위를 지정하는 방법은 아래와 같다. 범위를 생략해도 결과는 같지만, 성능이 저하된다.
ex) SUM(AMOUNT_SOLD) OVER(ORDER BY CUST_ID,CHANNEL_ID,TIME_ID ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
참고: Ranking family를 사용하여 WINDOW STOPKEY가 발생하는 경우는 SORT가 발생하지 않는 경우(NOSORT)뿐이다. 그룹분석함수에 의해서 추가적인 SORT를 해야 한다면, 전체범위로 처리됨으로 STOPKEY가 발생하지 않는다.
위의 다섯 가지 원리가 적용되지 않은 것이 각각의 비효율이다. 즉 위의 다섯 가지 원리를 비효율의 해결방법으로 작성한 사람은 100점이다.
자동튜닝기능이 아쉬워
이 글의 결론을 보고 많은 이들이 두 가지를 아쉬워할 것이다. 예컨대, 분석함수 SUM에 WINDOW의 범위를 생략했더라도 자동으로 ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW를 추가해 준다면 얼마나 좋을까? 불필요한 Partition By절을 수동으로 삭제해야 하는 것 또한 마찬가지이다. 아직까지 옵티마이저는 사람을 따라올 수 없다. 사람의 손길을 여전히 필요로 한다. 따라서 전문 개발자라면 Partition By나 Order By 혹은 Window의 범위지정 등의 코딩을 할 때 내부적으로 어떤 일이 발생하는지 알아야 한다. 그냥 코딩을 하는 사람과 그것이 성능상 어떤 의미를 지니는지 알고 개발하는 사람과는 차이가 크다.
이상으로 분석함수의 내부에 대해 3회에 걸쳐 알아보았다. 1부/2부의 내용과 위의 결론 다섯 가지를 완벽히 이해한다면, 분석함수를 사용한 SQL과 실행계획, 그리고 인덱스 구조만 보고도 순간적으로 비효율을 잡아낼 수 있다. 분석함수의 비효율을 만나면 번개가 치듯이 생각이 번쩍 들것이다. 실행계획을 보고 비효율의 냄새를 맡을 줄 아는 능력은 중요하다.
마지막으로, 분석함수의 실행계획에 관한 글을 의뢰한 개발자에게 감사를 표한다. 아무래도 내가 그 개발자에게 맥주를 사는 것이 더 좋을 것 같다. 왜냐하면 그 사람 덕분에 좋은 것(Window의 범위 지정의 효과)을 발견할 수 있었기 때문이다. 두서 없는 긴 글을 읽어주신 독자 여러분들께 감사 드린다.
------------------------------------------------------------------------------------------------------------------------------------------------
이번 글은 여기까지 이다. 아래의 글은 이전에 올렸던 글의 정답보다 더 좋은 것이 발견되었음을 알리는 것이다.
분석함수의 실행계획을 정리하면서 Group(SUM/MIN/MAX/AVG) 분석함수에 WINDOW의 범위를 명시적으로 작성하는 것이 얼마나 중요한지 필자도 깨닫게 되었다. 예컨대, Pagination과 분석함수의 위험한 조합 글에서 도출된 정답보다 더 좋은 것은 WINDOW의 범위를 명시하는 것이다. 따라서 분석함수를 밖으로 빼는 것보다, 아래와 같이 window의 범위를 지정해 주는 것이 더 유리하다.
SELECT *
FROM (SELECT s.*, ROWNUM rnum
FROM (SELECT /*+ INDEX(S PK_SALES_T) */
s.prod_id, s.cust_id, s.channel_id, s.time_id, amount_sold,
sum (amount_sold) OVER (PARTITION BY s.cust_id ORDER BY s.channel_id, s.time_id
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW ) AS sum_amt
FROM sales_t s
WHERE s.prod_id = :v_prod_id --> 30 대입
ORDER BY s.cust_id, s.channel_id, s.time_id
) s
WHERE ROWNUM <= :v_max_row --> 20 대입
)
WHERE rnum >= :v_min_row ; --> 1 대입
----------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | A-Rows | A-Time | Buffers | Used-Mem |
----------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 20 |00:00:00.01 | 24 | |
|* 1 | VIEW | | 1 | 20 |00:00:00.01 | 24 | |
|* 2 | COUNT STOPKEY | | 1 | 20 |00:00:00.01 | 24 | |
| 3 | VIEW | | 1 | 20 |00:00:00.01 | 24 | |
| 4 | WINDOW NOSORT | | 1 | 20 |00:00:00.01 | 24 | |
| 5 | TABLE ACCESS BY INDEX ROWID| SALES_T | 1 | 20 |00:00:00.01 | 24 | |
|* 6 | INDEX RANGE SCAN | PK_SALES_T | 1 | 20 |00:00:00.01 | 4 | |
----------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("RNUM">=:V_MIN_ROW)
2 - filter(ROWNUM<=:V_MAX_ROW)
6 - access("S"."PROD_ID"=:V_PROD_ID)
20건에 대해서 조차 SORT가 전혀 발생하지 않는다. 따라서 Pagination과 분석함수의 위험한 조합 이라는 글은 수정되어야만 한다. 내가 작성한 글을 내가 뒤집었다. 내 것이라도 비판적으로 바라보아야 한다. 최종이론이란 없는 것이므로
------------------------------------------------------------------------------------------------------------------------------------------------
Question: 어떻게 이런 책과 글을 쓰며, 주제는 어떻게 잡으며, 연구는 어떻게 하는가?
--> 이상한 질문이다. 내가 용빼는 재주라도 있나?
Answer:
필자의 머리가 좋아서 글을 쓸 수 있는 게 아니다. 오히려 그 반대이다. 똑똑한 다른 사람이라면, 내가 연구랍시고 소비한 시간의 절반만 투자해도 이 글을 썼을 것이다. 나는 다른 사람과 달리 영민하지 못하여 하찮은 문제에도 많은 시간을 소모하며, 실패하면 다시 조금씩 앞으로 전진 할 수 밖에 없다. 그렇다고 다른 재주가 있느냐 하면 그렇지 않다. 방향감각이 둔하여 연구가 막다른 길로 빠진 적이 여러 번일 뿐만 아니라 남들이 가지고 있는 창의성, 순발력, 영어실력, 문장력, 준수한 외모를 나는 가지지 못했고, 심지어 노래방에서는 박자를 못 맞추는 절대음감까지 그 어느 것도 잘하는 게 없다. 아무리 생각해도 세상은 불공평 한 듯 하다.
내가 할 수 있는 일은 나의 유일한 단점이자 장점을 살리는 수뿐이다. 실수를 하더라도, 거북이 근성으로 시간이 나는 대로 조금씩 연구를 하여 이런 글을 쓰는 수 밖에 없다. 글의 주제와 관련된 것도 특별한 것은 없다. 소주한잔 마시면서 어떤 글을 쓸지 동료들과 소통하거나, 독자들이 필요한 글을 나에게 요청한다. 내가 직접 글감을 고른 적은 5번중의 한번 정도이다. 글의 주제가 정해지면 무작정 글을 쓴다. 글을 쓰다가 모르는 것이 있으면(모르는 게 많다) 그에 맞춰 test(연구)를 한다. 궁금증이 해결되면 다시 글을 쓴다. 이것이 끝이다.
이 글도 위에서 설명한 절차와 똑같이 진행되었다. 단언하건대, 분석함수의 성능에 대해 이 문서만큼 깊이 다룬 책이나 매뉴얼은 지금까지 없다. 이런 일이 가능한 이유는 내가 아둔하고, 모르는 게 많은 거북이라서 그런 것이 아닐까?
'Oracle > Data Access Pattern' 카테고리의 다른 글
| 분석함수의 실행계획 - 심화과정 (12) | 2011.02.14 |
|---|---|
| 분석함수의 실행계획 - 2부 (12) | 2011.02.10 |
| 분석함수의 실행계획 - 1부 (13) | 2011.02.07 |
| Index_desc 힌트와 rownum = 1 조합은 안전한가? (12) | 2010.11.09 |
| Bloom Filter와 Group By의 관계 (10) | 2010.09.09 |


 invalid-file
invalid-file
 invalid-file
invalid-file