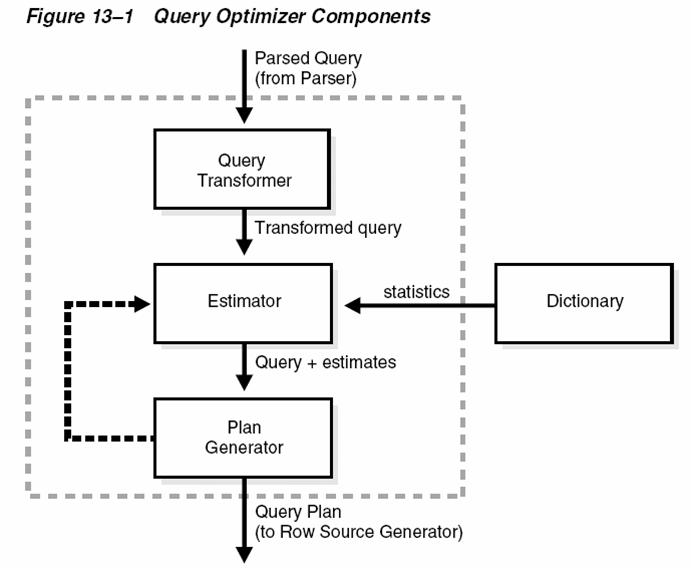
SQL에서 DISTINCT의 위치는 중요하다. DISTINCT가 메인쿼리에 위치하면 조인이 모두 처리된 후 DISTINCT가 실행된다.
그 반대로 각각의 집합을 DISTINCT 한 후에 조인한다면 양측 집합의 건수가 줄어들므로 조인의 부하가 줄어든다. 그런 관점에서 보면 아래의 SQL은 최악이다.
환경: ORACLE 11.2
DISTINCT c.channel_id, c.channel_desc, s.prod_id, s.promo_id
FROM channels c,
(SELECT /*+ qb_name(INLINE) NO_MERGE */
s.channel_id, s.prod_id, promo_id
FROM sales_t s
WHERE prod_id BETWEEN 13 AND 15) s
WHERE c.channel_id = s.channel_id ;
---------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | A-Rows | A-Time | Buffers | Used-Mem |
---------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 22 |00:00:00.22 | 22222 | |
| 1 | HASH UNIQUE | | 1 | 22 |00:00:00.22 | 22222 | 1271K (0)|
| 2 | NESTED LOOPS | | 1 | 17778 |00:00:00.21 | 22222 | |
| 3 | NESTED LOOPS | | 1 | 17778 |00:00:00.16 | 4444 | |
|* 4 | TABLE ACCESS FULL | SALES_T | 1 | 17778 |00:00:00.11 | 4440 | |
|* 5 | INDEX UNIQUE SCAN | CHANNELS_PK | 17778 | 17778 |00:00:00.03 | 4 | |
| 6 | TABLE ACCESS BY INDEX ROWID| CHANNELS | 17778 | 17778 |00:00:00.03 | 17778 | |
---------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
4 - filter(("PROD_ID">=13 AND "PROD_ID"<=15))
5 - access("C"."CHANNEL_ID"="S"."CHANNEL_ID")
위의 SQL을 보면 인라인뷰 S에 미리 건수를 줄이지 않아서 조인이 17778번 발생하였다. 다시 말해 조인하기 전에 인라인뷰 S에 DISTINCT 작업이 있었다면 조인을 22번만 하면 된다. 따라서 전체 DISTINCT 작업은 필요 없다. 아래는 튜닝된 SQL이다.
c.channel_id, c.channel_desc, s.prod_id, s.promo_id
FROM channels c,
(SELECT /*+ qb_name(inline) */
DISTINCT s.channel_id, s.prod_id, promo_id
FROM sales_t s
WHERE prod_id BETWEEN 13 AND 15) s
WHERE c.channel_id = s.channel_id ;
--------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | A-Rows | A-Time | Buffers | Used-Mem |
--------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 22 |00:00:00.12 | 4466 | |
| 1 | NESTED LOOPS | | 1 | 22 |00:00:00.12 | 4466 | |
| 2 | NESTED LOOPS | | 1 | 22 |00:00:00.12 | 4444 | |
| 3 | VIEW | | 1 | 22 |00:00:00.12 | 4440 | |
| 4 | HASH UNIQUE | | 1 | 22 |00:00:00.12 | 4440 | 1264K (0)|
|* 5 | TABLE ACCESS FULL | SALES_T | 1 | 17778 |00:00:00.11 | 4440 | |
|* 6 | INDEX UNIQUE SCAN | CHANNELS_PK | 22 | 22 |00:00:00.01 | 4 | |
| 7 | TABLE ACCESS BY INDEX ROWID| CHANNELS | 22 | 22 |00:00:00.01 | 22 | |
--------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
5 - filter(("PROD_ID">=13 AND "PROD_ID"<=15))
6 - access("C"."CHANNEL_ID"="S"."CHANNEL_ID")
미리 건수를 줄였으므로 22번만 조인하여 BLOCK I/O가 22222에서 4466으로 약 4~5배 줄어들었다. 이런 SQL 튜닝은 오라클 11.2에서는 더 이상 필요 없다. 아래의 SQL을 보자.
DISTINCT c.channel_id, c.channel_desc, s.prod_id, s.promo_id
FROM channels c,
(SELECT /*+ qb_name(inline) */
s.channel_id, s.prod_id, promo_id
FROM sales_t s
WHERE prod_id BETWEEN 13 AND 15) s
WHERE c.channel_id = s.channel_id ;
-------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | A-Rows | A-Time | Buffers | Used-Mem |
-------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 22 |00:00:00.09 | 4466 | |
| 1 | HASH UNIQUE | | 1 | 22 |00:00:00.09 | 4466 | 1218K (0)|
| 2 | NESTED LOOPS | | 1 | 22 |00:00:00.09 | 4466 | |
| 3 | NESTED LOOPS | | 1 | 22 |00:00:00.09 | 4444 | |
| 4 | VIEW | VW_DTP_2F839831 | 1 | 22 |00:00:00.09 | 4440 | |
| 5 | HASH UNIQUE | | 1 | 22 |00:00:00.09 | 4440 | 1283K (0)|
|* 6 | TABLE ACCESS FULL | SALES_T | 1 | 17778 |00:00:00.08 | 4440 | |
|* 7 | INDEX UNIQUE SCAN | CHANNELS_PK | 22 | 22 |00:00:00.01 | 4 | |
| 8 | TABLE ACCESS BY INDEX ROWID| CHANNELS | 22 | 22 |00:00:00.01 | 22 | |
-------------------------------------------------------------------------------------------------------------
Outline Data
-------------
/*+
BEGIN_OUTLINE_DATA
...생략
PLACE_DISTINCT(@"SEL$8FA4BC11" "S"@"INLINE")--> 2 DISTINCT를 추가한 뷰 VW_DTP_2F839831를 만듦
...생략
MERGE(@"INLINE") --> 1 먼저 MERGE를 진행함
...생략
END_OUTLINE_DATA
*/
Predicate Information (identified by operation id):
---------------------------------------------------
6 - filter(("PROD_ID"<=15 AND "PROD_ID">=13))
7 - access("C"."CHANNEL_ID"="ITEM_1")
SQL이 비효율 적으로 작성되었지만 Logical Optimizer가 Distinct를 추가하여 쿼리를 재 작성하였다. 이 쿼리변환을 Distinct Placement(DP) 라고 한다. DP는 주의해야 될 점이 있다. 인라인뷰 S를 해체(MERGE)하고 Distinct를 추가한 인라인뷰를 새로 만든다. 따라서 인라인뷰 S에 NO_MERGE 힌트를 사용한다면 결코 DP가 발생하지 않는다. 이 글에서 소개된 첫 번째 SQL에 NO_MERGE 힌트가 사용됨으로써 DP가 발생되지 않은 것이다.
DP는 약간의 비효율이 있다. 즉 필요 없는 전체 Distinct 작업이 수행된다. 실행계획을 보면 HASH UNIQUE가 두 번 존재하는데, 마지막 전체 Distinct(id 1번)는 필요 없다. SQL을 아래처럼 재 작성 하였기 때문에 불필요한 HASH UNIQUE가 추가된 것이다.
C.CHANNEL_ID CHANNEL_ID,
C.CHANNEL_DESC CHANNEL_DESC,
VW_DTP_2F839831.ITEM_2 PROD_ID,
VW_DTP_2F839831.ITEM_3 PROMO_ID
FROM (SELECT DISTINCT
S.CHANNEL_ID ITEM_1,
S.PROD_ID ITEM_2,
S.PROMO_ID ITEM_3
FROM TLO.SALES_T S
WHERE S.PROD_ID <= 50
AND S.PROD_ID >= 13
AND 50 >= 13) VW_DTP_2F839831,
TLO.CHANNELS C
WHERE C.CHANNEL_ID = VW_DTP_2F839831.ITEM_1 ;
따라서 아직까지는 사람이 튜닝하는 것을 따라올 수 없다.
힌트는 PLACE_DISTINCT/NO_PLACE_DISTINCT를 사용할 수 있으며 _optimizer_distinct_placement 파라미터로 기능을 컨트롤 할 수 있다. 이 파리미터의 Default값은 True이다. DP는 Cost Based Query Transformation에 속한다. Search Type과 Iteration이 존재하기 때문이다. 10053 Trace의 내용을 보면 더 확실히 알 수 있다.
|
****************************************
Cost-Based Group-By/Distinct Placement **************************************** GBP/DP: Checking validity of GBP/DP for query block SEL$8FA4BC11 (#1) GBP: Checking validity of group-by placement for query block SEL$8FA4BC11 (#1) GBP: Bypassed: Query has invalid constructs. DP: Checking validity of distinct placement for query block SEL$8FA4BC11 (#1) DP: Using search type: linear FPD: transitive predicates are generated in query block SEL$8FA4BC11 (#1) 먼저 DP가 실행될 수 있는지 Validity Checking을 한다. DP를 실행하는데 문제가 없다면 Iteration 1 에서 변환되지 않은 DP: Starting iteration 2, state space = (1) : (1) DP: Using DP transformation in this iteration. Registered qb: SEL$2F839831 0x11c3c2dc (QUERY BLOCK TABLES CHANGED SEL$8FA4BC11) --------------------- QUERY BLOCK SIGNATURE --------------------- signature (): qb_name=SEL$2F839831 nbfros=2 flg=0 fro(0): flg=0 objn=75859 hint_alias="C"@"MAIN" fro(1): flg=5 objn=0 hint_alias="VW_DTP_2F839831"@"SEL$2F839831" Registered qb: SEL$DC663686 0x11c3b800 (SPLIT/MERGE QUERY BLOCKS SEL$2F839831) Registered qb: SEL$7323A7B6 0x11c3c2dc (VIEW ADDED SEL$2F839831) Registered qb: SEL$10E34D75 0x11c3c2dc (DISTINCT PLACEMENT SEL$8FA4BC11; SEL$8FA4BC11; "S"@"INLINE") |
Iteration 2에는 DP가 적용된 SQL의 Cost를 구한다. 여기서 DP가 수행되는 절차를 QUERY BLOCK SIGNATURE에서 볼 수 있다. 먼저 VIEW MERGE가 발생된다.(MERGE QUERY BLOCKS 부분 참조) 그 후 SALES 테이블이 포함된 뷰를 메인쿼리에 추가한다.(VIEW ADDED 부분 참조). 마지막으로 추가된 인라인뷰에 Distinct를 추가한다. (DISTINCT PLACEMENT 부분 참조)
******* UNPARSED QUERY IS *******
SELECT /*+ QB_NAME ("INLINE") QB_NAME ("MAIN") */ DISTINCT "C"."CHANNEL_ID" "CHANNEL_ID","C"."CHANNEL_DESC" "CHANNEL_DESC","VW_DTP_2F839831"."ITEM_2" "PROD_ID","VW_DTP_2F839831"."ITEM_3" "PROMO_ID" FROM (SELECT DISTINCT "S"."CHANNEL_ID" "ITEM_1","S"."PROD_ID" "ITEM_2","S"."PROMO_ID" "ITEM_3" FROM "TLO"."SALES_T" "S" WHERE "S"."PROD_ID"<=15 AND "S"."PROD_ID">=13) "VW_DTP_2F839831","TLO"."CHANNELS" "C" WHERE "C"."CHANNEL_ID"="VW_DTP_2F839831"."ITEM_1"
FPD: Considering simple filter push in query block SEL$10E34D75 (#1)
"C"."CHANNEL_ID"="VW_DTP_2F839831"."ITEM_1"
try to generate transitive predicate from check constraints for query block SEL$10E34D75 (#1)
finally: "C"."CHANNEL_ID"="VW_DTP_2F839831"."ITEM_1"
...생략
kkoqbc: finish optimizing query block SEL$10E34D75 (#1)
CBQT: Saved costed qb# 2 (SEL$DC663686), key = SEL$DC663686_00001000_2
CBQT: Saved costed qb# 1 (SEL$10E34D75), key = SEL$10E34D75_00000008_0
DP: Updated best state, Cost = 1236.23
DP: Doing DP on the preserved QB.
이로써 졸저 The Logical Optimizer의 416페이지 미해결 과제에서 약속한 것을 지켰다. DP의 예제가 발견되면 블로그와 책에 반영하기로 약속 했었다. 출력을 해서 책의 416페이지에 끼워넣기 바란다. 2011년에 DP를 발견했지만 여러가지 문제로 반영하지 못하다가 이제서야 올리게 되었다. 사과드린다.
'The Logical Optimizer' 카테고리의 다른 글
| The Logical Optimizer-Part 4 PPT (10) | 2010.10.04 |
|---|---|
| The Logical Optimizer-Part 3 PPT (5) | 2010.09.15 |
| Heuristic Query Transformation-PPT (11) | 2010.08.12 |
| Null Aware Hash Anti Join에 관한 오해 (0) | 2010.08.06 |
| NULL AWARE ANTI JOIN은 SQL을 어떻게 변경시키나? (2) | 2010.08.02 |
 invalid-file
invalid-file