SF 영화 트랜스포머를 보면 자동차가 로봇으로 변환하는 과정이 있다. 자동차와 로봇간의 변환과정은 아주 현란하다 못해 활홍하여 시청자자로 하여금 넋을 놓고 빠져들게 한다. 컴퓨터그래픽(CG) 기술의 발전 덕분이다.
변환과정이 있어야 지구를 지킬수 있어
만약 이 영화에서 자동차가 로봇으로 변환을 못한다고 상상해보자. 악한 로봇이 쳐들어와도 싸울수가 없고 격렬한 전투장면도 사라진다. 이래서는 영화가 재미없을 뿐더러 지구를 지킬수도 없다. 그럼 오라클에서 Query Transformer 가 없어진다면 어떻게 될까? 마찬가지로 Query 의 상당부분을 튜닝할수 없게 되어 전체 시스템이 느려지게된다. Query Transformer 의 목적은 성능향상에 있다.
오라클에도 트랜스포머가 있다.
오라클 Optimizer 에서 Query Transformer 는 3대 Components 로서 아주 중요한 위치에 있다.
먼저 Query Transformer 를 이해하기 위해서 Optimizer 구조를 살펴볼 필요가 있다.
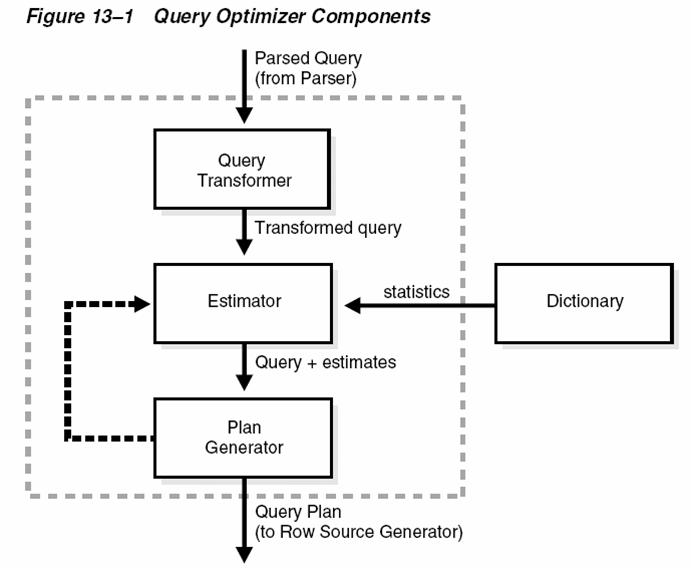
먼저 Query Parser 가 SQL 을 검사하여 넘겨주면 Transformer 가 SQL 을 변신시켜서 Estimator 에 넘겨준다.
이때 Estimator는 통계정보등을 참조하여 가장 낮은 cost 를 갖는 SQL 을 찾아내어 Plan Generator 에 넘겨주고 실행계획을 완성하게 된다. 사실 위의 그림은 오라클 Performance Tuning Guide 에 있는 그림 이지만 잘못된 것이 있다. Query Transformer 가 Estimator 에게 주는 SQL 은 하나이상이 될수 있으므로 Estimator 와 Plan Generator 의 관계처럼 반복적인 Loop 가 있어야 한다.
변환과정도 로봇에 따라 다양하다.
트랜스포머에서 주인공 로봇의 변환과정은 아주 복잡하다. 하지만 소형 악당 로봇이 카세트 레코더로 변환하는 과정을 유심히 보았는가? 이 과정은 매우 간단하다. 오라클의 쿼리변환(Query Transformation) 과정도 간단한 것에서 부터 아주 복잡한 과정을 거치는 것 까지 다양하다.
구슬이 서말이라도 꿰어야 보배
오늘은 조금 어려운 다단계 쿼리변환-(Muti-Phase-Query Transformation)에 대하여 알아보려 한다.
참고로 아래의 글이 이해하기 힘든 독자는 필자의 이전글 Using Sub query Method (Sub query Flattening ) 과 Using Sub query Method( Filter / Access sub Query ) 를 먼저 읽어보기 바란다.
그럼 각 단계별로 변환과정을 보자.
1 단계 : 원본 쿼리
자신이 속한 부서의 평균급여 보다 돈을 많이 받는 사원을 추출하는 예제이다.
from emp outer
where outer.sal > ( select /*+ NO_UNNEST */ avg(inner.sal)
from emp inner
where inner.deptno = outer.deptno
);
--------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | A-Rows | A-Time | Buffers |
--------------------------------------------------------------------------------------------
|* 1 | FILTER | | 1 | 5 |00:00:00.01 | 16 |
| 2 | TABLE ACCESS FULL | EMP | 1 | 14 |00:00:00.01 | 8 |
| 3 | SORT AGGREGATE | | 5 | 5 |00:00:00.01 | 8 |
| 4 | TABLE ACCESS BY INDEX ROWID| EMP | 5 | 13 |00:00:00.01 | 8 |
|* 5 | INDEX RANGE SCAN | IX_EMP_N3 | 5 | 13 |00:00:00.01 | 3 |
--------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("OUTER"."SAL">)
5 - access("INNER"."DEPTNO"=:B1)
전통적인 Filter Subquery(확인자 SubQuery) 이다.
2.단계 : 서브쿼리를 인라인뷰로 바꿔라.
이 단계에서 unnest 힌트를 사용함으로서 Subquery 가 인라인뷰로 바뀌며 서브쿼리가 없어진다. 이때 메인쿼리의 건수를 유지하기 위해 인라인뷰에 group by 가 추가된다.
from emp outer
where outer.sal > ( select /*+ QB_NAME(SUB) UNNEST */ avg(inner.sal)
from emp inner
where inner.deptno = outer.deptno
);
-----------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | A-Rows | A-Time | Buffers | Used-Mem |
-----------------------------------------------------------------------------------------------------
|* 1 | TABLE ACCESS BY INDEX ROWID| EMP | 1 | 5 |00:00:00.01 | 16 | |
| 2 | NESTED LOOPS | | 1 | 19 |00:00:00.09 | 10 | |
| 3 | VIEW | VW_SQ_1 | 1 | 5 |00:00:00.01 | 7 | |
| 4 | HASH GROUP BY | | 1 | 5 |00:00:00.01 | 7 | 1622K (0)|
| 5 | TABLE ACCESS FULL | EMP | 1 | 14 |00:00:00.01 | 7 | |
|* 6 | INDEX RANGE SCAN | IX_EMP_N3 | 5 | 13 |00:00:00.01 | 3 | |
-----------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("OUTER"."SAL">"VW_COL_1")
6 - access("DEPTNO"="OUTER"."DEPTNO")
filter("OUTER"."DEPTNO" IS NOT NULL)
이것은 Optimizer가 쿼리를 아래처럼 변형시킨것이다.
outer.*
from emp outer,
( select deptno, avg(sal) AS VW_COL_1
from emp
group by deptno
) A
where outer.sal > A.VW_COL_1
and outer.deptno = A.deptno ;
-----------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | A-Rows | A-Time | Buffers | Used-Mem |
-----------------------------------------------------------------------------------------------------
|* 1 | TABLE ACCESS BY INDEX ROWID| EMP | 1 | 5 |00:00:00.01 | 16 | |
| 2 | NESTED LOOPS | | 1 | 19 |00:00:00.13 | 10 | |
| 3 | VIEW | | 1 | 5 |00:00:00.01 | 7 | |
| 4 | HASH GROUP BY | | 1 | 5 |00:00:00.01 | 7 | 1622K (0)|
| 5 | TABLE ACCESS FULL | EMP | 1 | 14 |00:00:00.01 | 7 | |
|* 6 | INDEX RANGE SCAN | IX_EMP_N3 | 5 | 13 |00:00:00.01 | 3 | |
-----------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("OUTER"."SAL">"A"."VW_COL_1")
6 - access("OUTER"."DEPTNO"="A"."DEPTNO")
filter("OUTER"."DEPTNO" IS NOT NULL)
2단계의 원본 쿼리와 Plan 이 일치함을 알수 있다.
3단계 : 인라인뷰를 해체하라.
MERGE 힌트를 사용함으로서 2단계에서 Unnesting 된 인라인뷰를 해체하여 조인으로 바뀌었다. 이것을 View Merging 이라고 부른다.
outer.*
from emp outer
where outer.sal > ( select /*+ QB_NAME(SUB) UNNEST */ avg(inner.sal)
from emp inner
where inner.deptno = outer.deptno
);
다시말하면 위의 쿼리를 Optimizer가 아래처럼 재작성 한것이다.
outer.deptno deptno,outer.sal sal,
outer.empno empno
from emp inner,
emp outer
where inner.deptno=outer.deptno
group by inner.deptno, outer.rowid, outer.empno, outer.sal, outer.deptno
having outer.sal > avg(inner.sal) ;
메인쿼리의 결과집합을 보존하기위하여 rowid 로 Group by 를 한것에 유의하자.
두개의 Query Plan 은 동일하며 아래와 같다.
-----------------------------------------------------------------------------------------------
| Id | Operation | Name | A-Rows | A-Time | Buffers | Used-Mem |
-----------------------------------------------------------------------------------------------
|* 1 | FILTER | | 5 |00:00:00.01 | 12 | |
| 2 | HASH GROUP BY | | 13 |00:00:00.01 | 12 | 1103K (0)|
| 3 | MERGE JOIN | | 51 |00:00:00.01 | 12 | |
| 4 | TABLE ACCESS BY INDEX ROWID| EMP | 13 |00:00:00.01 | 5 | |
|* 5 | INDEX FULL SCAN | IX_EMP_N3 | 13 |00:00:00.01 | 1 | |
|* 6 | SORT JOIN | | 51 |00:00:00.01 | 7 | 2048 (0)|
|* 7 | TABLE ACCESS FULL | EMP | 13 |00:00:00.01 | 7 | |
-----------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("OUTER"."SAL">AVG("INNER"."SAL"))
5 - filter("INNER"."DEPTNO" IS NOT NULL)
6 - access("INNER"."DEPTNO"="OUTER"."DEPTNO")
filter("INNER"."DEPTNO"="OUTER"."DEPTNO")
7 - filter("OUTER"."DEPTNO" IS NOT NULL)
드디어 1~3 단계에 걸친 Query Transformation 단계가 완성 되었다. 그결과는 성능면에서 대성공이다. Buffers(읽은 Block수) 가 16(원본쿼리) 에서 12 로 약 25% 감소했다.
오라클 트랜스포머는 악성쿼리와 싸워...
오라클 Query Transformer 는 SQL 을 멋지게 변화시켰다. 이모든 과정을 개발자가 해야한다고 상상해보자.
개발자들에게 전체과정을 이해시키는 교육과정이 추가되어야 하고 개발속도는 몇배나 느려질것이다. 이는 프로젝트의 Risk 가 될것이다. 하지만 오라클 Query Transformer 가 있으므로 악당 로봇이 아닌 악성쿼리와 멋지게 싸워서 이길수 있는 것이다.
편집후기 :
Query Transformation 을 하려면 반드시 unnesting 이나 merge 힌트를 써야 하는지 질문이 들어왔다. 대부분의 경우 Query Transformer 가 자동으로 변환과정을 수행해준다. 하지만 이것이 가끔 제대로 수행이 안될수 있으므로 이럴경우에만 명시적으로 힌트를 사용하는것이 바람직하다.
'Oracle > Optimizer' 카테고리의 다른 글
| PM ( Predicate Move Around ) : Where 조건을 다른뷰에 이동시켜라. (2) | 2009.06.09 |
|---|---|
| Query Transformation Internal ( about JPPD using Lateral View ) (0) | 2009.04.20 |
| Access Sub Query 의 함정 (4) | 2008.11.19 |
| 오라클은 얼마나 똑똑한가? (3) | 2008.10.10 |
| Using Sub query Method( Filter / Access sub Query ) (9) | 2008.09.29 |