Query Transformer 의 냉대
튜닝을 하는 많은 사람들이 PM 의 개념을 모른다는 결과가 나왔다. 정기모임 술자리에서 즉석으로 설문을 하였는데 결과는 충격적이었다. 참석자 10명은 DBA, 튜너, DB 컨설턴트 등등 DB 전문가들의 모임이라고 할수 있는데 단 한명도 아는사람이 없었다.
필자가 충격적이라고 한 이유는 그모임의 많은 사람들이 왠만한 SQL 의 COST 를 계산할수 있는 내공을 가진 사람들이 었기 때문이다. 다행히 JPPD 나 VIEW MERGING, Unnesting 과 같이 튜닝 책에 소개 되는 간단한 변환들은 알고 있었다. 하지만 Query Transformer 가 푸배접을 받고 있다는 생각은 지울수가 없었다.
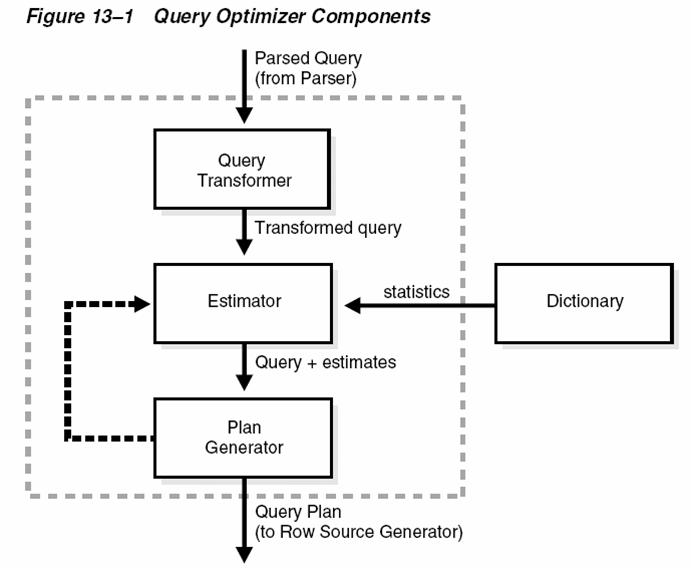
Query Transformer 는 그 중요성이 옵티마이져의 50% 를 차지한다. 왜그럴까? 옵티마이져의 3대 Components 는 Query Transformer, Cost Estimator, Plan Generator 이지만 이중에서 우리가 연구할수 있는 것은 Query Transformer 와 Cost Estimator 이며 Plan Generator 의 비밀은 오라클사의 DBMS 설계자/개발자만이 알수 있는 영역이기 때문이다. 또한 SQL 이 Transformer 에 의하여 변형되고 재작성 되기 때문에 성능에 직접적인 영향을 끼친다. 대부분의 경우 Query Transformation 이 발생하면 성능에 긍정적인 영향을 끼치지만 예외적으로 부정정인 영향을 줄수가 있으므로 가능한 Query Transformer에 대하여 상세히 알아야 한다.
어찌되었건 모임에서 PM 관련 내용을 블로그에 올리겠다는 약속을 하였다.
PM ( Predicate Move Around ) 이란?
인라인뷰가 여러 개 있고 각각의 where 절에 공통적인 조건들이 있다고 가정하자.
이럴경우에 모든 인라인뷰의 where 절에 똑 같은 조건들을 반복해서 사용해야 할까?
물론 그렇게 해야 하는 경우가 있지만 아래의 경우에는 그렇지 않음을 알수 있다..
SELECT /*+ qb_name (v_outer) */
v1.*
FROM (SELECT /*+ qb_name (IV1) no_merge */
e1.*, d1.location_id
FROM employee e1, department d1
WHERE e1.department_id = d1.department_id
AND d1.department_id = 30
) v1,
(SELECT /*+ qb_name (IV2) no_merge */
d2.department_id, AVG (salary) avg_sal_dept
FROM employee e2, department d2, loc l2
WHERE e2.department_id = d2.department_id
AND l2.location_id = d2.location_id
GROUP BY d2.department_id
) v2
WHERE v1.department_id = v2.department_id
AND v1.salary > v2.avg_sal_dept ;
----------------------------------------------------------+----------------------------------+
| Id | Operation | Name | Rows | Bytes | Cost | Time |
----------------------------------------------------------+----------------------------------+
| 0 | SELECT STATEMENT | | | | 5 | |
| 1 | HASH JOIN | | 1 | 176 | 5 | 00:00:01|
| 2 | VIEW | | 1 | 28 | 2 | 00:00:01|
| 3 | HASH GROUP BY | | 1 | 21 | 2 | 00:00:01|
| 4 | NESTED LOOPS | | | | | |
| 5 | NESTED LOOPS | | 6 | 126 | 2 | 00:00:01|
| 6 | NESTED LOOPS | | 1 | 14 | 1 | 00:00:01|
| 7 | INDEX RANGE SCAN | DEPT_IX_01 | 1 | 11 | 1 | 00:00:01|
| 8 | INDEX UNIQUE SCAN | LOC_ID_PK | 23 | 69 | 0 | |
| 9 | INDEX RANGE SCAN | EMP_DEPARTMENT_IX| 6 | | 0 | |
| 10 | TABLE ACCESS BY INDEX ROWID| EMPLOYEES | 6 | 42 | 1 | 00:00:01|
| 11 | VIEW | | 6 | 888 | 2 | 00:00:01|
| 12 | NESTED LOOPS | | | | | |
| 13 | NESTED LOOPS | | 6 | 474 | 2 | 00:00:01|
| 14 | INDEX RANGE SCAN | DEPT_IX_01 | 1 | 11 | 1 | 00:00:01|
| 15 | INDEX RANGE SCAN | EMP_DEPARTMENT_IX| 6 | | 0 | |
| 16 | TABLE ACCESS BY INDEX ROWID | EMPLOYEES | 6 | 408 | 1 | 00:00:01|
----------------------------------------------------------+----------------------------------+
Predicate Information:
----------------------
1 - access("V1"."DEPARTMENT_ID"="V2_DEPT"."DEPARTMENT_ID")
1 - filter("V1"."SALARY">"V2_DEPT"."AVG_SAL_DEPT")
7 - access("D2"."DEPARTMENT_ID"=30)
8 - access("L2"."LOCATION_ID"="D2"."LOCATION_ID")
9 - access("E2"."DEPARTMENT_ID"=30)
14 - access("D1"."DEPARTMENT_ID"=30)
15 - access("E1"."DEPARTMENT_ID"=30)
다른뷰에 조건이 추가되었다.
Predicate Information을 보면 두번째 뷰(v2 ) 에 "D2"."DEPARTMENT_ID"=30 조건과 "E2"."DEPARTMENT_ID"=30 조건이 파고들어 간 것을 알수 있다. 이 현상 때문에 D1 과 E1 에서 인덱스를 사용하였는데 결과는 성능면에서 아주 성공적이다. 그렇다면 오라클은 어떤 과정을 거쳐서 이작업을 진행하였을까?
10053 trace 정보를 보면 PM의 진행과정이 매우 상세하게 나와 있다.
PM: Considering predicate move-around in query block V_OUTER (#1)
**************************
Predicate Move-Around (PM)
**************************
PM: Passed validity checks.
PM: Pulled up predicate "V1"."DEPARTMENT_ID"=30
from query block IV1 (#2) to query block V_OUTER (#1)
PM: Pushed down predicate "D2"."DEPARTMENT_ID"=30
from query block V_OUTER (#1) to query block IV2 (#3)
PM 은 순서가 중여하다.
10053 trace 내용을 분석하여 수행과정을 살펴보자.
1. 먼저 PM 이 수행될수 있는지 검사한다.
2. V1 에서 WHERE 조건 d1.department_id = 30 를 바깥쪽 메인쿼리로 이동시킨다.
이것을 Predicate pull up 이라고 한다.
3. 메인쿼리로 옮겨진 where 조건을 v2 에 복사한다.
이것을 Predicate Push down 이라고 한다.
4. 최종 결과에서 중복된 조건절이 존재하면 삭제한다..
V1, V2 가 메인쿼리(V_OUTER)에서 department_id 기준으로 조인되고 있기 때문에 조건절을 V_OUTER 로 빼낸 다음에 V2 에 조건절을 밀어 넣고 있다. 이것은 JPPD 기능과 유사한 면이 있지만 Predicate pull up 이 반드시 먼저 일어나야 한다는 점과 Hash 조인등에서도 PM 이 발생한다는 점에서 엄연히 다르다. 오라클은 여러분이 모르는 사이에 조건절을 이리 저리 옮겨 다니면서 SQL 의 최적화를 시도하고 있다.
PM 아무때나 발생하나?
그럼 PM 이 어떤 조건일 경우 발생하는지 짐작할수 있겠는가?
다음과 같은 조건일 경우 PM 이 발생된다.
1. 뷰(혹은 인라인뷰) 가 2개 혹은 그이상이 되어야 한다.(예제에서 V1, V2 가 있음)
2. 특정 인라인뷰내의 조건이 존재하고 뷰의 바깥쪽에서 조건을 사용한 컬럼으로 조인이 발생할 경우에 발생된다. 예제에서 는 d1.department_id = 30 으로 V1 내부에 조건이 존재하고 V_OUTER 에서 department_id 로 V2 와 조인을 하고 있다.
3. VIEW MERGE 가 발생하지 않아야 한다. Merging 이 발생되면 PM 대신에 Transitive Predicates 가 발생된다.
4. 파라미터 _PRED_MOVE_AROUND 가 true 로 지정이 되어 있어야 한다.
결론 :
제목에서 보듯이 PM 의 개념은 매우 간단하다. Where 조건을 다른뷰에 이동시키는 기능이며 Heuristic Transformatin 의 대표적인 예제이다.
오늘 올린 글은 현재 집필중인 책의 내용인데 일부를 먼저 공개하기로 결정 하였다.
편집후기 : JPPD 와 PM 이 헷갈린다는 보고가 들어왔다. 둘다 WHERE 조건이 PUSH 되는것이지만 가장 결정적이 차이점은 JPPD 는 Predicate pull up 기능이 없다는 것이다. 아주 명확하게 구분할수 있다.

 invalid-file
invalid-file