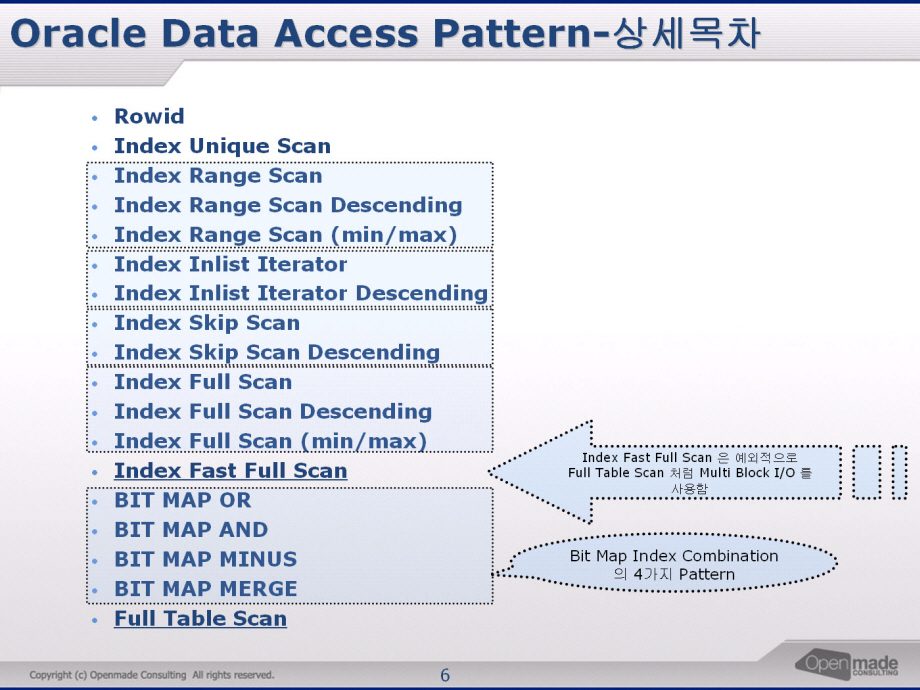
질문을 받다
독자로 부터 다음과 같은 질문을 받았다. "MERGE 문에 IN 조건을 사용한다면 아래의 Plan처럼 심각한 성능저하가 발생 하였다. 왜그런가?"
--------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads |
--------------------------------------------------------------------------------------------------
| 1 | MERGE | T2 | 1 | | 2 |00:25:50.73 | 50M| 821 |
| 2 | VIEW | | 1 | | 100K|00:25:52.38 | 50M| 795 |
| 3 | NESTED LOOPS OUTER | | 1 | 100K| 100K|00:25:52.28 | 50M| 795 |
|* 4 | TABLE ACCESS FULL | T1 | 1 | 100K| 100K|00:00:00.60 | 316 | 629 |
| 5 | VIEW | | 100K| 1 | 100K|00:25:34.26 | 50M| 166 |
|* 6 | FILTER | | 100K| | 100K|00:25:33.92 | 50M| 166 |
|* 7 | TABLE ACCESS FULL| T2 | 100K| 1 | 100K|00:25:33.68 | 50M| 166 |
--------------------------------------------------------------------------------------------------
T1의 조건을 만족하는 건수만큼 T2가 FULL SCAN을 반복하고 있다. 이것은 재앙이나 다름없다. 어떤 원리로 성능저하가 발생하는지 MERGE문을 실행할 때 내부적으로 발생하는 일들의 특징과 순서를 알아보자.
무조건 아우터 조인이 발생해
MERGE문을 실행하면 Target 쪽 테이블에는 무조건 아우터 조인으로 바뀐다. 왜냐하면 Match 되지 않는 경우(조인에 실패한 경우)에도 INSERT 해야 하기 때문이다. 그리고 아우터 조인은 다시 LATERAL VIEW로 바뀐다. 왜냐하면 View Merging이 실패할 경우 FPD(Filter Push Down)이나 JPPD(JOIN PREDICATE PUSH DOWN)이 적용 되어야 하기 때문이다. LATERAL VIEW의 개념은 아래의 POST를 참조하라.
http://scidb.tistory.com/entry/Outer-Join-의-재조명
쿼리변환 순서가 중요하다
아래는 MERGE문 실행시 쿼리변환이 발생하는 순서 이다.
1.먼저 Transformer(Logical Optimizer)는 IN 조건을 OR 로 바꾼다.
2.TRANSFORMER(Logical Optimizer)는 아우터 조인되는 쪽을 LATERAL VIEW로 바꾼다.
3.LATERAL VIEW가 해체(View Merging이라 불림) 되어 평범한 아우터 조인으로 바뀐다. 이때 View Merging에 실패하면 심각한 성능저하가 발생할 수 있다. 위의 Plan을 보면 T2 쪽의 View 가 해체되지 못했다. 이것이 실마리가 될 것이다.
아래의 스크립트를 실행하여 실제로 이런 일들이 발생하는지 Test 환경을 만들어 보자.
create table t1(c1 varchar2(10), c2 int, c3 int, c4 int);
create table t2(c1 varchar2(10), c2 int, c3 int, c4 int);
insert into t1
select decode(mod(level,2),0,'A','B'), level, level, level
from dual connect by level <= 100000
;
insert into t2
select decode(mod(level,2),0,'A','B'), level, level, level
from dual connect by level <= 100000
;
analyze table t1 compute statistics;
analyze table t2 compute statistics;
Merge 문을 사용해보자
-- case 1
MERGE /*+ gather_plan_statistics */ INTO t2
USING (SELECT *
FROM t1
WHERE c1 IN ('A', 'B')) x
ON ( x.c1 = t2.c1
AND x.c2 = t2.c2
AND x.c3 = t2.c3
AND t2.c1 = 'A')
WHEN MATCHED THEN
UPDATE SET t2.c4 = x.c4
WHEN NOT MATCHED THEN
INSERT (t2.c1, t2.c2, t2.c3, t2.c4)
VALUES (x.c1, x.c2, x.c3, x.c4) ;
select *
from table(dbms_xplan.display_cursor(null,null,'allstats last')) ;
-----------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | A-Rows | A-Time | Buffers | Reads | Used-Mem |
-----------------------------------------------------------------------------------------------------
| 1 | MERGE | T2 | 1 | 2 |00:00:12.52 | 105K| 655 | |
| 2 | VIEW | | 1 | 100K|00:00:00.65 | 632 | 626 | |
|* 3 | HASH JOIN RIGHT OUTER| | 1 | 100K|00:00:00.65 | 632 | 626 | 4686K (0)|
|* 4 | TABLE ACCESS FULL | T2 | 1 | 50000 |00:00:00.02 | 316 | 313 | |
|* 5 | TABLE ACCESS FULL | T1 | 1 | 100K|00:00:00.01 | 316 | 313 | |
-----------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("T1"."C3"="T2"."C3" AND "T1"."C2"="T2"."C2" AND "T1"."C1"="T2"."C1")
4 - filter("T2"."C1"='A')
5 - filter(("C1"='A' OR "C1"='B'))
아주 정상적인 PLAN 이다.
Merge 문에 IN 조건을 사용해보자
-- case 2
MERGE /*+ gather_plan_statistics */ INTO t2
USING (SELECT *
FROM t1
WHERE c1 IN ('A', 'B')) x
ON ( x.c1 = t2.c1
AND x.c2 = t2.c2
AND x.c3 = t2.c3
AND t2.c1 IN ('A', 'B'))
WHEN MATCHED THEN
UPDATE SET t2.c4 = x.c4
WHEN NOT MATCHED THEN
INSERT (t2.c1, t2.c2, t2.c3, t2.c4)
VALUES (x.c1, x.c2, x.c3, x.c4) ;
--------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads |
--------------------------------------------------------------------------------------------------
| 1 | MERGE | T2 | 1 | | 2 |00:25:50.73 | 50M| 821 |
| 2 | VIEW | | 1 | | 100K|00:25:52.38 | 50M| 795 |
| 3 | NESTED LOOPS OUTER | | 1 | 100K| 100K|00:25:52.28 | 50M| 795 |
|* 4 | TABLE ACCESS FULL | T1 | 1 | 100K| 100K|00:00:00.60 | 316 | 629 |
| 5 | VIEW | | 100K| 1 | 100K|00:25:34.26 | 50M| 166 |
|* 6 | FILTER | | 100K| | 100K|00:25:33.92 | 50M| 166 |
|* 7 | TABLE ACCESS FULL| T2 | 100K| 1 | 100K|00:25:33.68 | 50M| 166 |
--------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
4 - filter(("C1"='A' OR "C1"='B'))
6 - filter(("T1"."C1"='A' OR "T1"."C1"='B'))
7 - filter(("T1"."C1"="T2"."C1" AND "T1"."C2"="T2"."C2" AND "T1"."C3"="T2"."C3" AND
INTERNAL_FUNCTION("T2"."C1")))
10만번 반복된다
Starts 항목에 주목하라 FTS(Full Table Scan)을 10만번 반복 실행하였다. CASE2 에서 t2.c1 IN ('A', 'B') 조건을 사용하였더니 최악의 PLAN이 만들어 졌으며 Buffers 가 50M 에 육박하고 시간상으로도 25분 이상 걸렸다. 왜 그럴까? 아래의 SQL처럼 Case1과 Case2 실행시에 Logical Optimizer에 의하여 변경된 SQL을 보면 이유를 알수 있다.
SELECT /*+ CASE1 NO_MERGE 상태 */
lv.RID,
lv.C1, lv.C2, lv.C3, lv.C4,
X.C1, X.C2, X.C3, X.C4
FROM (SELECT T1.C1 C1,T1.C2 C2,T1.C3 C3,T1.C4 C4
FROM T1
WHERE T1.C1='A' OR T1.C1='B'
) X,
LATERAL( SELECT T2.C1, T2.C2, T2.C3, T2.C4, T2.ROWID AS RID
FROM T2
WHERE X.C1=T2.C1
AND X.C2=T2.C2
AND X.C3=T2.C3
AND T2.C1='A' )(+) lv
정상적으로 뷰가 해체되다
Case1의 LATERAL VIEW 내부의 T2.C1='A' 조건은 아우터 조인으로 바꿀 수 있으므로 View Merging이 발생하여 인라인뷰 X와 LATERAL VIEW lv가 아래처럼 평범한 아우터 조인으로 바뀐다.
SELECT /*+ CASE1 MERGE 상태 */
T2.ROWID RID,
T2.C1 ,T2.C2 C2,T2.C3 C3,T2.C4 C4,
T1.C1 ,T1.C2 C2,T1.C3 C3,T1.C4 C4
FROM T1, T2
WHERE T1.C3=T2.C3(+)
AND T1.C2=T2.C2(+)
AND T1.C1=T2.C1(+)
AND T2.C1(+)='A'
AND (T1.C1='A' OR T1.C1='B')
이때 옵티마이져가 내부적으로 MERGE 힌트를 사용한다. 10053 Trace에도 다음처럼 쿼리블럭 SEL$2 와 SEL$3이 SEL$1에 MERGE 되었다는 정보가 포함되어 있다.
Registered qb: SEL$5428C7F1 0x9f7b318 (VIEW MERGE SEL$1; SEL$2 SEL$3)
Out Line 정보에도 이런 사항이 잘 나타난다.
Outline Data
-------------
/*+
…생략
MERGE(@"SEL$2") --> 쿼리블럭 2 와
MERGE(@"SEL$3") --> 쿼리블럭 3 이 MERGE 되어 LATERAL VIEW 가 없어짐
…생략
*/
이제 case 2를 분석 해보자.
SELECT /*+ CASE2 NO_MERGE 상태 */
lv.RID,
lv.C1, lv.C2, lv.C3, lv.C4,
X.C1, X.C2, X.C3, X.C4
FROM (SELECT T1.C1 C1,T1.C2 C2,T1.C3 C3,T1.C4 C4
FROM T1
WHERE T1.C1='A' OR T1.C1='B') X,
LATERAL( SELECT T2.C1, T2.C2, T2.C3, T2.C4, T2.ROWID AS RID
FROM T2
WHERE X.C1=T2.C1
AND X.C2=T2.C2
AND X.C3=T2.C3
AND (T2.C1='A' OR T2.C1='B') ) (+) lv
제약조건 때문에...
위의 SQL 은 LATERAL VIEW를 적용한 모습이다. 그런데 (T2.C1='A' OR T2.C1='B') 조건 때문에 아우터 조인으로 바꾸질 못한다. 이것은 오라클 제약사항 이다. 제약조건이 있을 경우는 View Merging이 실패한다. 아래처럼 말이다.
SELECT /*+ CASE2 MERGE 상태 */
lv.RID,
lv.C1, lv.C2, lv.C3, lv.C4,
X.C1, X.C2, X.C3, X.C4
FROM T1,
LATERAL( SELECT T2.C1, T2.C2, T2.C3, T2.C4, T2.ROWID AS RID
FROM T2
WHERE X.C1=T2.C1
AND X.C2=T2.C2
AND X.C3=T2.C3
AND (T2.C1='A' OR T2.C1='B') ) (+) lv
WHERE T1.C1='A' OR T1.C1='B'
IN 이 발목을 잡다
인라인뷰 X 만 View Merging이 발생하였다. 결국 IN 혹은 OR 조건이 View Merging이 되지 못하도록 발목을 잡은 셈이다. 그리하여 Lateral View 가 살아남게 되었다. Lateral View는 스칼라 서브쿼리처럼 동작하게 된다. 다시 말하면 LATERAL VIEW 는 Hash 조인으로 실행되지 못한다. 문제의 Plan에서 Nested Loop 조인이 발생한 이유도 여기 있다.
그렇다면 이 문제를 어떻게 해결할 수 있을까?
문제 해결방법 3가지
1) 만약 인덱스를 만들 수 있다면 문제가 해결된다. 아래는 T2 에 (C1, C2, C3) 인덱스를 만든후 CASE 2를 다시 실행한 Plan 이다.
-----------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | A-Rows | A-Time | Buffers | Reads |
-----------------------------------------------------------------------------------------------------
| 1 | MERGE | T2 | 1 | 2 |00:00:16.95 | 303K| 934 |
| 2 | VIEW | | 1 | 100K|00:00:03.92 | 200K| 932 |
| 3 | NESTED LOOPS OUTER | | 1 | 100K|00:00:03.92 | 200K| 932 |
|* 4 | TABLE ACCESS FULL | T1 | 1 | 100K|00:00:00.12 | 316 | 313 |
| 5 | VIEW | | 100K| 100K|00:00:02.51 | 200K| 619 |
|* 6 | FILTER | | 100K| 100K|00:00:02.29 | 200K| 619 |
| 7 | TABLE ACCESS BY INDEX ROWID| T2 | 100K| 100K|00:00:02.09 | 200K| 619 |
|* 8 | INDEX RANGE SCAN | T2_IDX | 100K| 100K|00:00:01.24 | 100K| 320 |
-----------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
4 - filter(("C1"='A' OR "C1"='B'))
6 - filter(("T1"."C1"='A' OR "T1"."C1"='B'))
8 - access("T1"."C1"="T2"."C1" AND "T1"."C2"="T2"."C2" AND "T1"."C3"="T2"."C3")
filter(("T2"."C1"='A' OR "T2"."C1"='B'))
2) 인덱스를 만들 수 없는 경우라면 아래처럼 Between 을 사용하면 된다. Between 은 아우터 조인이 가능하다.
MERGE /*+ gather_plan_statistics */ INTO t2
USING (SELECT *
FROM t1
WHERE c1 IN ('A', 'B')) x
ON ( x.c1 = t2.c1
AND x.c2 = t2.c2
AND x.c3 = t2.c3
AND t2.c1 between 'A' AND 'B')
WHEN MATCHED THEN
UPDATE SET t2.c4 = x.c4
WHEN NOT MATCHED THEN
INSERT (t2.c1, t2.c2, t2.c3, t2.c4)
VALUES (x.c1, x.c2, x.c3, x.c4) ;
--------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | A-Rows | A-Time | Buffers | Reads | Used-Mem |
--------------------------------------------------------------------------------------------------
| 1 | MERGE | T2 | 1 | 2 |00:00:14.99 | 104K| 817 | |
| 2 | VIEW | | 1 | 100K|00:00:00.58 | 816 | 810 | |
|* 3 | HASH JOIN OUTER | | 1 | 100K|00:00:00.48 | 816 | 810 | 7600K (0)|
|* 4 | TABLE ACCESS FULL| T1 | 1 | 100K|00:00:00.01 | 316 | 313 | |
|* 5 | TABLE ACCESS FULL| T2 | 1 | 100K|00:00:00.01 | 500 | 497 | |
--------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("T1"."C3"="T2"."C3" AND "T1"."C2"="T2"."C2" AND "T1"."C1"="T2"."C1")
4 - filter(("C1"='A' OR "C1"='B'))
5 - filter(("T2"."C1"<='B' AND "T2"."C1">='A'))
정상적으로 Hash 조인이 발생하였다.
3) Between 을 사용할 수 없는 경우라면 아래처럼 Decode를 사용하면 된다. Decode 또한 아우터 조인이 가능하다.
MERGE /*+ gather_plan_statistics */ INTO t2
USING (SELECT *
FROM t1
WHERE c1 IN ('A', 'B')) x
ON ( x.c1 = t2.c1
AND x.c2 = t2.c2
AND x.c3 = t2.c3
AND t2.c1 = decode(t2.c1, 'A', 'A', 'B'))
WHEN MATCHED THEN
UPDATE SET t2.c4 = x.c4
WHEN NOT MATCHED THEN
INSERT (t2.c1, t2.c2, t2.c3, t2.c4)
VALUES (x.c1, x.c2, x.c3, x.c4) ;
-----------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | A-Rows | A-Time | Buffers | Reads | Used-Mem |
-----------------------------------------------------------------------------------------------------
| 1 | MERGE | T2 | 1 | 2 |00:00:15.16 | 104K| 967 | |
| 2 | VIEW | | 1 | 100K|00:00:00.72 | 816 | 810 | |
|* 3 | HASH JOIN RIGHT OUTER| | 1 | 100K|00:00:00.72 | 816 | 810 | 8568K (0)|
|* 4 | TABLE ACCESS FULL | T2 | 1 | 100K|00:00:00.02 | 500 | 497 | |
|* 5 | TABLE ACCESS FULL | T1 | 1 | 100K|00:00:00.01 | 316 | 313 | |
-----------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("T1"."C3"="T2"."C3" AND "T1"."C2"="T2"."C2" AND "T1"."C1"="T2"."C1")
4 - filter("T2"."C1"=DECODE("T2"."C1",'A','A','B'))
5 - filter(("C1"='A' OR "C1"='B'))
정상적으로 Hash 조인이 발생하였다.
결론
Merge문 사용시 On 절에 Target 테이블의 조건으로 IN 이나 OR를 사용하면 View Merging 이 발생하지 않는다. 따라서 LATERAL VIEW가 해체되지 못하며 LATERAL VIEW의 특성상 Nested Loop 조인이 적용된다. 이때 후행 테이블은 적절한 인덱스가 없다면 Full Table Scan이 발생하여 재앙과 같은 성능저하 현상이 발생된다. 이때 BETWEEN 이나 DECODE등 상황에 맞는 해결책을 사용할 수 있다.
모르면 못한다
결국 Query Transformation의 원리와 순서 그리고 제약조건을 알게 된다면 누가 해법을 말해주지 않아도 자연스럽게 알 수 있다. IN 과 OR의 아우터 조인 제약조건은 누구나 알고 있으므로 문제가 될수 없다. 문제는 Query Transformation을 모른다면 튜닝을 못하는 시대가 이미 왔다는 사실이다. 안타깝게도 이런 원리를 설명해주는 서적은 어디에도 없다. 물론 몇가지 Query Transformation을 소개한 책은 있지만 Logical Optimizer를 주제로 하는 서적은 없다. 다시 말하면 우리는 튜닝을 하지 못할 환경에 살고 있다.

 invalid-file
invalid-file

 invalid-file
invalid-file
 invalid-file
invalid-file




