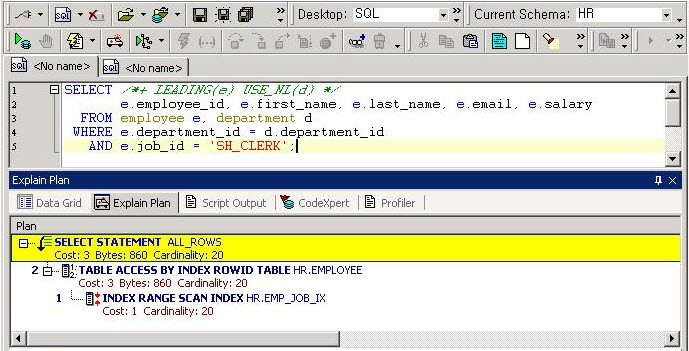
Query Transformation을 모르면 튜닝을 할 수 없다
위의 말을 보고 많은 독자들이 말도 안 된다고 생각할 것이다. Logical Optimizer와 그 결과물인 Query Transformation을 잘 알지 못했지만 지금껏 튜닝을 성공적으로 했다고 생각하는 사람이 많이 있기 때문이다. 하지만 과연 그럴까? 아래의 SQL 을 보고 Query Transformation 과 Logical Optimizer 가 얼마나 중요한지 알아보자.
여기서 한단계 더 나아가서 뷰(인라인뷰가 아니다) 내부의 테이블에 대하여 조인순서 및 Access Path 를 바꿀 수 있는 방법에 대해 논의 해보자.
준비
테스트를 위하여 인덱스 3개와 뷰 하나를 만들자.
CREATE INDEX loc_postal_idx ON location (postal_code);
CREATE INDEX dept_name_idx ON department (department_name);
CREATE INDEX coun_region_idx ON country (region_id);
CREATE OR REPLACE VIEW v_dept AS
SELECT d.department_id, d.department_name, d.manager_id, l.location_id,
l.postal_code, l.city, c.country_id, c.country_name, c.region_id
FROM department d, location l, country c
WHERE d.location_id = l.location_id
AND l.country_id = c.country_id;
실행시켜보자
이제 모든 준비가 끝났다. 아래는 매우 짧고 쉬운 SQL 이다. SQL을 실행시키고 연이어DBMS_XPLAN.display_cursor 를 실행한 후의 결과 중에서 필요한 부분만 발췌 하였다.
SELECT /*+ gather_plan_statistics */
e.employee_id, e.first_name, e.last_name, e.job_id, v.department_name
FROM employee e, v_dept v
WHERE e.department_id = v.department_id
AND v.department_name = 'Shipping'
AND v.postal_code = '99236'
AND v.region_id = 2
AND e.job_id = 'ST_CLERK';
---------------------------------------------------------------------------------------------
| Id | Operation | Name | A-Rows | A-Time | Buffers |
---------------------------------------------------------------------------------------------
| 1 | NESTED LOOPS | | 20 |00:00:00.01 | 11 |
| 2 | NESTED LOOPS | | 45 |00:00:00.01 | 8 |
| 3 | NESTED LOOPS | | 1 |00:00:00.01 | 6 |
| 4 | NESTED LOOPS | | 1 |00:00:00.01 | 5 |
| 5 | TABLE ACCESS BY INDEX ROWID| DEPARTMENT | 1 |00:00:00.01 | 3 |
|* 6 | INDEX RANGE SCAN | DEPT_NAME_IDX | 1 |00:00:00.01 | 2 |
|* 7 | TABLE ACCESS BY INDEX ROWID| LOCATION | 1 |00:00:00.01 | 2 |
|* 8 | INDEX UNIQUE SCAN | LOC_ID_PK | 1 |00:00:00.01 | 1 |
|* 9 | INDEX UNIQUE SCAN | COUNTRY_C_ID_PK | 1 |00:00:00.01 | 1 |
|* 10 | INDEX RANGE SCAN | EMP_DEPARTMENT_IX | 45 |00:00:00.01 | 2 |
|* 11 | TABLE ACCESS BY INDEX ROWID | EMPLOYEE | 20 |00:00:00.01 | 3 |
---------------------------------------------------------------------------------------------
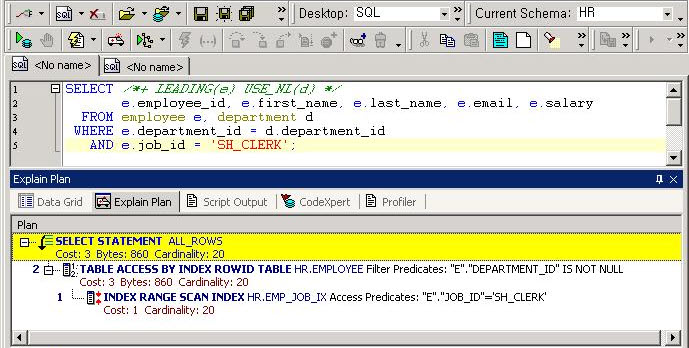
Predicate Information (identified by operation id):
---------------------------------------------------
6 - access("D"."DEPARTMENT_NAME"='Shipping')
7 - filter("L"."POSTAL_CODE"='99236')
8 - access("D"."LOCATION_ID"="L"."LOCATION_ID")
9 - access("L"."COUNTRY_ID"="C"."COUNTRY_ID")
filter("C"."REGION_ID"=2)
10 - access("E"."DEPARTMENT_ID"="D"."DEPARTMENT_ID")
11 - filter("E"."JOB_ID"='ST_CLERK')
조인순서를 바꿀 수 있겠는가
위의 실행계획에서 조인순서는 V_dept --> Employee 이다. 만약 이 상태에서 여러분이 조인의 순서를 Employee --> V_dept 로 바꿀 수 있겠는가? 아마 아래처럼 힌트를 사용할 것이다.
SELECT /*+ gather_plan_statistics LEADING(E V) */
e.employee_id, e.first_name, e.last_name, e.job_id, v.department_name
..이후생략
---------------------------------------------------------------------------------------------
| Id | Operation | Name | A-Rows | A-Time | Buffers |
---------------------------------------------------------------------------------------------
| 1 | NESTED LOOPS | | 45 |00:00:00.01 | 11 |
| 2 | NESTED LOOPS | | 45 |00:00:00.01 | 8 |
| 3 | NESTED LOOPS | | 1 |00:00:00.01 | 6 |
| 4 | NESTED LOOPS | | 1 |00:00:00.01 | 5 |
| 5 | TABLE ACCESS BY INDEX ROWID| DEPARTMENT | 1 |00:00:00.01 | 3 |
|* 6 | INDEX RANGE SCAN | DEPT_NAME_IDX | 1 |00:00:00.01 | 2 |
|* 7 | TABLE ACCESS BY INDEX ROWID| LOCATION | 1 |00:00:00.01 | 2 |
|* 8 | INDEX UNIQUE SCAN | LOC_ID_PK | 1 |00:00:00.01 | 1 |
|* 9 | INDEX UNIQUE SCAN | COUNTRY_C_ID_PK | 1 |00:00:00.01 | 1 |
|* 10 | INDEX RANGE SCAN | EMP_DEPARTMENT_IX | 45 |00:00:00.01 | 2 |
| 11 | TABLE ACCESS BY INDEX ROWID | EMPLOYEE | 45 |00:00:00.01 | 3 |
---------------------------------------------------------------------------------------------
힌트가 무시 되었다 원인은?
조인의 순서가 전혀 변하지 않았다. 이상하지 않은가? 간단하게 생각되는 SQL의 조인순서도 변경할 수 없다. 이유는 Query Transformation 때문이다. Outline 정보를 보면 실마리를 찾을 수 있다.
Outline Data
-------------
/*+
BEGIN_OUTLINE_DATA
…중간생략
MERGE(@"SEL$2")
…중간생략
END_OUTLINE_DATA
*/
원인은 Logical Optimizer 에 의한 Query Transformation 이다
뷰 V_dept 에 View Merging 이 발생한 것이다. View Merging은 Query Transformation 의 한 종류이며 뷰를 해체하여 정상적인 조인으로 바꾸는 작업이다. Query Transformation이 발생하면 많은 경우에 쿼리블럭명이 바뀌어 버린다. 따라서 바뀐 쿼리블럭명을 지정하여 힌트를 사용하거나 Query Transformation 이 발생하지 않게 하면 힌트가 제대로 적용된다.
SELECT /*+ gather_plan_statistics NO_MERGE(V) LEADING(E V) */
e.employee_id, e.first_name, e.last_name, e.job_id, v.department_name
FROM employee e, v_dept v
WHERE e.department_id = v.department_id
AND v.department_name = 'Shipping'
AND v.postal_code = '99236'
AND v.region_id = 2
AND e.job_id = 'ST_CLERK';
-------------------------------------------------------------------------------------------
| Id | Operation | Name | A-Rows | A-Time | Buffers |
-------------------------------------------------------------------------------------------
|* 1 | HASH JOIN | | 20 |00:00:00.02 | 8 |
| 2 | TABLE ACCESS BY INDEX ROWID | EMPLOYEE | 20 |00:00:00.02 | 2 |
|* 3 | INDEX RANGE SCAN | EMP_JOB_IX | 20 |00:00:00.02 | 1 |
| 4 | VIEW | V_DEPT | 1 |00:00:00.01 | 6 |
| 5 | NESTED LOOPS | | 1 |00:00:00.01 | 6 |
| 6 | NESTED LOOPS | | 1 |00:00:00.01 | 5 |
| 7 | TABLE ACCESS BY INDEX ROWID| DEPARTMENT | 1 |00:00:00.01 | 3 |
|* 8 | INDEX RANGE SCAN | DEPT_NAME_IDX | 1 |00:00:00.01 | 2 |
|* 9 | TABLE ACCESS BY INDEX ROWID| LOCATION | 1 |00:00:00.01 | 2 |
|* 10 | INDEX UNIQUE SCAN | LOC_ID_PK | 1 |00:00:00.01 | 1 |
|* 11 | INDEX UNIQUE SCAN | COUNTRY_C_ID_PK | 1 |00:00:00.01 | 1 |
-------------------------------------------------------------------------------------------
Query Transformation 이 발생하지 않으면 조인순서 변경이 가능해
No_merge 힌트를 사용하여 Query Transformation 이 발생하지 않게 하였더니 조인 순서가 Employee --> V_dept 로 바뀌었다. 이제 알겠는가? Query Transformation과 Logical Optimizer를 모른다면 힌트도 먹통이 된다. 이래서는 제대로 된 튜닝을 할 수 없다.
뷰 내부의 테이블에 대한 조인순서의 변경은 가능한가
한 단계 더 나아가 보자. No_merge 힌트를 사용한 상태에서 뷰 내부의 테이블들에 대해서 조인순서를 바꾸고 싶다. 즉 조인순서를 Employee --> 뷰(Country --> Location --> Department) 로 바꾸어야 한다. 이때 여러분은 어떻게 할 것인가? 아래처럼 Global Hint 를 사용하면 된다.
SELECT /*+ gather_plan_statistics NO_MERGE(V) LEADING(E V) LEADING(V.C V.L V.D) */
e.employee_id, e.first_name, e.last_name, e.job_id, v.department_name
FROM employee e, v_dept v
WHERE e.department_id = v.department_id
AND v.department_name = 'Shipping'
AND v.postal_code = '99236'
AND v.region_id = 2
AND e.job_id = 'ST_CLERK';
Leading 힌트를 두 번 사용하였다. 그 이유는 위의 SQL은 쿼리블럭 2개로 구성되어 있기 때문이다. 즉 전체 SQL 에 대한 Leading 힌트가 필요하며 V_dept 에 대한 Leading 힌트가 각각 필요하다. V_dept 에 대한 Leading 힌트를 사용할 때 Dot 표기법을 사용해야 한다. 즉 뷰 내부에 존재하는 테이블들의 Alias 를 사용해야 한다. 이 방법은 Global Hint 사용 방법 중에 Dot 표기법을 사용한 것이다.
--------------------------------------------------------------------------------------------
| Id | Operation | Name | A-Rows | A-Time | Buffers |
--------------------------------------------------------------------------------------------
|* 1 | HASH JOIN | | 20 |00:00:00.01 | 9 |
| 2 | TABLE ACCESS BY INDEX ROWID | EMPLOYEE | 20 |00:00:00.01 | 2 |
|* 3 | INDEX RANGE SCAN | EMP_JOB_IX | 20 |00:00:00.01 | 1 |
| 4 | VIEW | V_DEPT | 1 |00:00:00.01 | 7 |
| 5 | NESTED LOOPS | | 1 |00:00:00.01 | 7 |
| 6 | NESTED LOOPS | | 1 |00:00:00.01 | 6 |
|* 7 | HASH JOIN | | 1 |00:00:00.01 | 4 |
|* 8 | INDEX RANGE SCAN | COUN_REGION_IDX | 5 |00:00:00.01 | 1 |
| 9 | TABLE ACCESS BY INDEX ROWID| LOCATION | 1 |00:00:00.01 | 3 |
|* 10 | INDEX RANGE SCAN | LOC_POSTAL_IDX | 1 |00:00:00.01 | 2 |
|* 11 | INDEX RANGE SCAN | DEPT_NAME_IDX | 1 |00:00:00.01 | 2 |
|* 12 | TABLE ACCESS BY INDEX ROWID | DEPARTMENT | 1 |00:00:00.01 | 1 |
--------------------------------------------------------------------------------------------
Global Hint 는 매우 유용해
성공적으로 조인순서가 Employee --> 뷰(Country --> Location --> Department)로 바뀌었다. Global Hint 를 사용하자 힌트가 제대로 적용된다. 이 방법은 특히 뷰나 인라인뷰를 Control 할 때 유용하므로 반드시 익혀두기 바란다.
Query Transformation 이 발생했을 경우는 힌트를 어떻게 적용할 수 있나
이제 원래 목적인 Query Transformation 이 발생했을 경우에 조인순서를 바꾸는 방법에 대해 논의 해보자. 위에서 배운 Global Hint 를 여기에 적용할 것이다.
SELECT /*+ gather_plan_statistics LEADING(E V.C V.L V.D) */
e.employee_id, e.first_name, e.last_name, e.job_id, v.department_name
FROM employee e, v_dept v
WHERE e.department_id = v.department_id
AND v.department_name = 'Shipping'
AND v.postal_code = '99236'
AND v.region_id = 2
AND e.job_id = 'ST_CLERK';
위의 SQL은 No_merge 힌트가 사라졌으므로 Query Transformation 이 발생된다. 그래서 위에서 배운 대로 Dot 표기법을 활용하여 Leading 힌트를 사용 하였다. 힌트가 적용될까?
---------------------------------------------------------------------------------------------
| Id | Operation | Name | A-Rows | A-Time | Buffers |
---------------------------------------------------------------------------------------------
| 1 | NESTED LOOPS | | 20 |00:00:00.01 | 11 |
| 2 | NESTED LOOPS | | 45 |00:00:00.01 | 8 |
| 3 | NESTED LOOPS | | 1 |00:00:00.01 | 6 |
| 4 | NESTED LOOPS | | 1 |00:00:00.01 | 5 |
| 5 | TABLE ACCESS BY INDEX ROWID| DEPARTMENT | 1 |00:00:00.01 | 3 |
|* 6 | INDEX RANGE SCAN | DEPT_NAME_IDX | 1 |00:00:00.01 | 2 |
|* 7 | TABLE ACCESS BY INDEX ROWID| LOCATION | 1 |00:00:00.01 | 2 |
|* 8 | INDEX UNIQUE SCAN | LOC_ID_PK | 1 |00:00:00.01 | 1 |
|* 9 | INDEX UNIQUE SCAN | COUNTRY_C_ID_PK | 1 |00:00:00.01 | 1 |
|* 10 | INDEX RANGE SCAN | EMP_DEPARTMENT_IX | 45 |00:00:00.01 | 2 |
|* 11 | TABLE ACCESS BY INDEX ROWID | EMPLOYEE | 20 |00:00:00.01 | 3 |
---------------------------------------------------------------------------------------------
실패사례: 힌트가 무시 되었다
힌트가 전혀 먹혀 들지 않는다. 그 이유는 View Merging이 발생하여 새로운 쿼리블럭이 생성되었기 때문이다. 아래의 Query Block Name 정보를 보면 쿼리블럭명과 각 테이블의 Alias 를 조회할 수 있다. / 를 기준으로 왼쪽이 쿼리블럭명이고 오른쪽이 각 테이블의 Alias 이다. 제일 왼쪽의 숫자는 실행계획상의 Id 와 일치한다.
Query Block Name / Object Alias (identified by operation id):
-------------------------------------------------------------
1 - SEL$F5BB74E1
5 - SEL$F5BB74E1 / D@SEL$2
6 - SEL$F5BB74E1 / D@SEL$2
7 - SEL$F5BB74E1 / L@SEL$2
8 - SEL$F5BB74E1 / L@SEL$2
9 - SEL$F5BB74E1 / C@SEL$2
10 - SEL$F5BB74E1 / E@SEL$1
11 - SEL$F5BB74E1 / E@SEL$1
힌트에 쿼리블럭명과 Object의 Alias를 사용해야 가능해
쿼리블럭명은 SEL$F5BB74E1 이며 Object의 Alias 들은 D@SEL$2, L@SEL$2, C@SEL$2, E@SEL$1 임을 알 수 있다. 따라서 이 정보들을 이용하여 아래처럼 힌트를 바꾸어 보자.
SELECT /*+ gather_plan_statistics LEADING(@SEL$F5BB74E1 E@SEL$1 C@SEL$2 L@SEL$2 D@SEL$2 ) */
e.employee_id, e.first_name, e.last_name, e.job_id, v.department_name
FROM employee e, v_dept v
WHERE e.department_id = v.department_id
AND v.department_name = 'Shipping'
AND v.postal_code = '99236'
AND v.region_id = 2
AND e.job_id = 'ST_CLERK';
위의 힌트처럼 쿼리블럭명을 처음에 지정하고 그 뒤에는 조인될 순서대로 Object Alias 를 배치하기만 하면 된다.
------------------------------------------------------------------------------------------
| Id | Operation | Name | A-Rows | A-Time | Buffers |
------------------------------------------------------------------------------------------
|* 1 | HASH JOIN | | 20 |00:00:00.01 | 8 |
|* 2 | HASH JOIN | | 20 |00:00:00.01 | 5 |
| 3 | MERGE JOIN CARTESIAN | | 100 |00:00:00.01 | 3 |
| 4 | TABLE ACCESS BY INDEX ROWID| EMPLOYEE | 20 |00:00:00.01 | 2 |
|* 5 | INDEX RANGE SCAN | EMP_JOB_IX | 20 |00:00:00.01 | 1 |
| 6 | BUFFER SORT | | 100 |00:00:00.01 | 1 |
|* 7 | INDEX RANGE SCAN | COUN_REGION_IDX | 5 |00:00:00.01 | 1 |
| 8 | TABLE ACCESS BY INDEX ROWID | LOCATION | 1 |00:00:00.01 | 2 |
|* 9 | INDEX RANGE SCAN | LOC_POSTAL_IDX | 1 |00:00:00.01 | 1 |
| 10 | TABLE ACCESS BY INDEX ROWID | DEPARTMENT | 1 |00:00:00.01 | 3 |
|* 11 | INDEX RANGE SCAN | DEPT_NAME_IDX | 1 |00:00:00.01 | 2 |
------------------------------------------------------------------------------------------
쿼리블럭 표기법은 Leading Hint 뿐만 아니라 모든 힌트에 적용 가능해
조인 순서가 Employee --> Country --> Location --> Department 로 바뀌었다. 이 방법은 Global Hint 사용 방법 중에 쿼리블럭 표기법을 사용한 것이다. 이 방법은 특히 View Merging 과 같은 Query Transformation 이 발생하여 쿼리블럭이 새로 생성된 경우 매우 유용하다. 이 방법으로 모든 힌트를 사용할 수 있다. 아래의 Outline Data 는 이런 점을 잘 설명 해준다.
Outline Data
-------------
/*+
…중간생략
MERGE(@"SEL$2")
…중간생략
INDEX_RS_ASC(@"SEL$F5BB74E1" "E"@"SEL$1" ("EMPLOYEE"."JOB_ID"))
INDEX(@"SEL$F5BB74E1" "C"@"SEL$2" ("COUNTRY"."REGION_ID"))
…중간생략
USE_HASH(@"SEL$F5BB74E1" "D"@"SEL$2")
END_OUTLINE_DATA
*/
PS
위의 내용 또한 이번에 출간될 책의 일부분이다. 블로그에 책의 내용이 많이 올라가서 걱정이다.^^


 invalid-file
invalid-file
 invalid-file
invalid-file






